PCI Express 8.0: Powering AI, Cloud, and HPC with Transformative Interconnect Technology


Introduction
We are living through a data revolution that’s fundamentally changing how we design and build technology. From the neural networks that power tomorrow’s autonomous vehicles to the massive computational clusters that train the next generation AI models, one truth has become crystal clear: the bottleneck is not just about processing power anymore—it’s how fast we can move data between components.
Consider this: a single modern GPU can process terabytes of information per second, but if the interconnect can’t keep pace, that computational muscle goes waste. Meanwhile, automotive engineers are grappling with sensor arrays that generate more raw data than many enterprise servers, all the while demanding real-time processing for safety-critical decisions. In data centres, the race to deploy larger AI models has created an insatiable appetite for bandwidth that current infrastructure is struggling to satisfy.
This is where PCI Express 8.0 enters the picture—not just as another incremental upgrade, but as a fundamental leap forward in interconnect technology. By doubling data rates to an unprecedented 256 GT/s per lane, PCIe Gen8 promises to unlock new possibilities across industries, from enabling more sophisticated AI training workflows to supporting the complex, multi-sensor ecosystems that will define next-generation vehicles.
But speed alone is not enough. As we’ll explore, PCIe 8.0 represents a carefully engineered balance of raw performance, backward compatibility, and the signal integrity challenges that come with pushing data rates to unprecedented levels. This is where Siemens plays a crucial role in the ecosystem. Through our advanced PCIe verification IP solutions and comprehensive testing frameworks, Siemens is helping semiconductor companies and system designers ensure their PCIe 8.0 implementations meet the stringent reliability and performance requirements that the next-generation applications demand. Our verification technologies are instrumental in bridging the gap between theoretical specifications and real-world deployment and ensure that the promise of 1 TB/s bandwidth translates into reliable, production-ready systems.
Let’s dive into what makes this technology so transformative—and why robust verification, powered by solutions from Siemens, is essential for realizing the full potential of PCIe 8.0.
What is PCIe? Why PCIe Gen8 Represents a Critical Inflection Point?
If you have ever wondered what keeps the inside of a modern computer talking to itself and its peripherals at blistering speeds, the answer is almost certainly PCIe — Peripheral Component Interconnect Express.
It is the high-speed serial communication standard that connects your CPU to the rest of the world: GPUs, SSDs, network cards, FPGAs, and a growing constellation of specialized accelerators. First introduced in 2003 as a successor to the aging PCI and AGP buses, PCIe was designed from the ground-up to be fast, scalable, and future-ready. And over the past two decades, it has delivered on that promise — repeatedly.
Each generation doesn’t just bring faster speeds — it unlocks entirely new categories of applications that were previously bottlenecked by bandwidth. And with PCIe 8.0, we are standing at one of the most consequential inflection points in computing history.
- AI & Machine Learning: Modern AI workloads face a critical challenge that goes beyond raw computational power: the ability to efficiently move massive datasets between processing units, memory hierarchies, and storage systems. PCIe 8.0’s bandwidth capabilities enable more straightforward scaling approaches that allow, AI researchers to focus on model architecture rather than working around I/O constraints.
- Cloud & Data Centres: Computational storage devices and storage-class memory technologies require interconnects that can support both high-bandwidth data movement and low-latency command processing—capabilities that PCIe 8.0 is specifically designed to address.
- High-Performance Computing (HPC): Scientific computing applications—from climate modelling to pharmaceutical research—increasingly rely on heterogeneous computing architectures that combine CPUs, GPUs, and specialized accelerators. These systems require seamless data movement between diverse processing elements to maintain computational efficiency. PCIe 8.0 enables new HPC architectures where accelerators can be more tightly coupled, reducing the data movement overhead that currently limits many scientific applications.
- Future-Ready: Perhaps most importantly, PCIe 8.0 provides the infrastructure foundation for technologies that are still emerging. Quantum-classical hybrid computing systems, neuromorphic processors, and advanced sensor fusion platforms will all require interconnect capabilities that exceed current standards.
Advanced PCIe 8.0 Feature Support and Comprehensive Debug Capabilities
Siemens QuestaTM One Avery Verification IP is leading the industry with the verification solution for almost all protocols and their associated Compliance Testsuite (CTS) and checklists, that collectively are FIRST, FAST, EXPERT, and TRUSTED, as mentioned below:
- FIRST — solutions for leading edge
- FAST — native SV/UVM code, fast debug and support turnaround
- EXPERT — direct access to our Protocol Experts
- TRUSTED — finding bugs that other VIPs do not find
PCIe 8.0 draft 0.5 features that Avery PCIE VIP supports
- PIPE and Serial interface support
- All equalization Modes supported till 256 GT/s data rate (Gen8)
- Full Equalization
- Equalization Bypass
- No Equalization
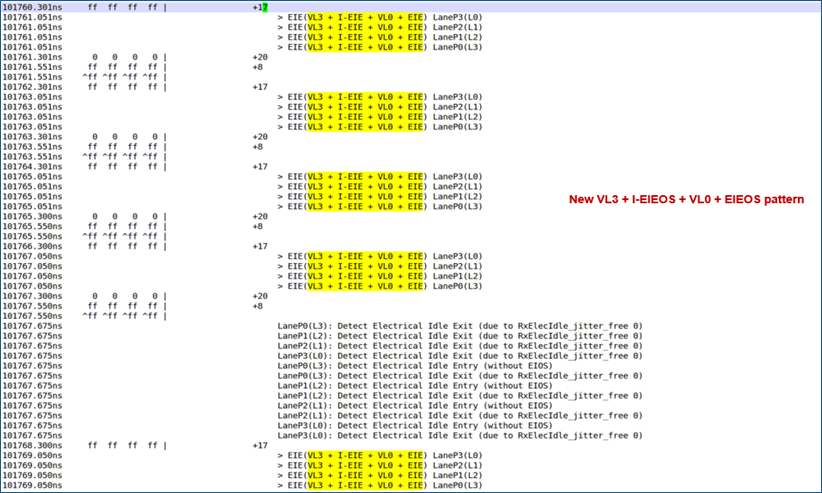
- EIEOSQ: VL3 + I-EIEOS +VL0+ EIEOS
- Dynamic link partition: 2×8 links at 256 GT/s
- Precoding support
- Loopback and Polling compliance Support
- Support of Optical retimer and 4 FRA retimers
- Security Stack: SPDM, IDE-KM, IDE, and TDISP
Key Benefits of Choosing Avery PCIe VIP
The Avery PCIe VIP provides the following key benefits:
- Class-based BFM and easy to integrate
- Random configuration capabilities
- Compliance Test Suites that include randomized tests
- 7000+ checklists items with 1400+ Compliance Tests
- Proven track record of finding Design IP bugs
- Full stack Callbacks at TL, DL, PL layer, adding error injection capabilities
- Multiple trackers for each layer TL, DL and PL
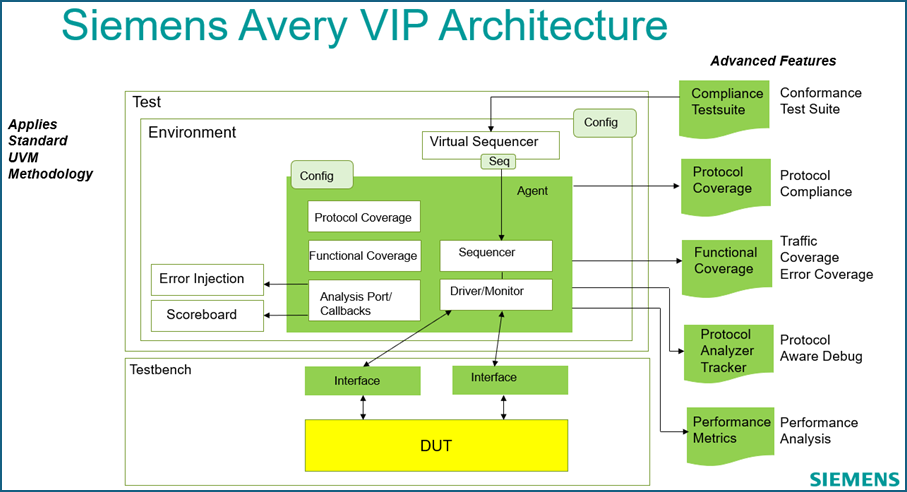
The following figure illustrates the Siemens Avery VIP architecture.
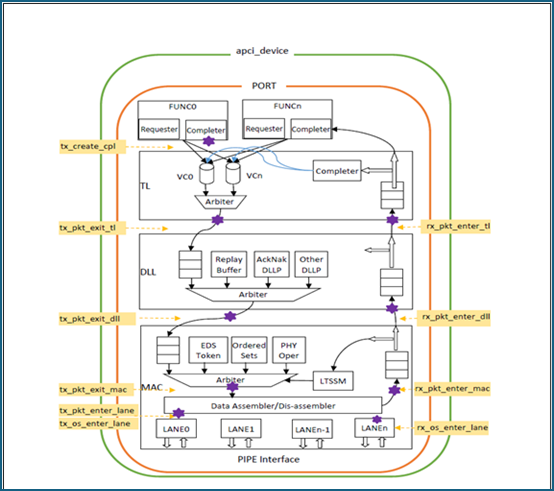
The following figure illustrates the callbacks.
The following figure shows the Gen8 EIEOSQ pattern.
Conclusion
As PCIe 8.0 sets new standards for interconnect performance, Siemens Questa One Avery Verification IP delivers a comprehensive toolset needed for comprehensive verification. Our advanced VIP solution combines full PCIe 8.0 feature support with intelligent debug capabilities that enables efficient verification of even the most complex designs. The powerful analysis and troubleshooting tools of Avery PCIe VIP help engineers quickly identify and resolve issues, ensuring robust system performance.
Trust Siemens QuestaTM One Avery VIP to provide the verification excellence required for your PCIe 8.0 designs.


Comments
Leave a Reply
You must be logged in to post a comment.
Excellent deep dive into PCIe 8.0 architecture. The jump to 64 GT/s per lane with PAM4 signaling is remarkable — but as data rates climb, the physical layer demands on connector and channel design become absolutely critical. Signal integrity at these speeds requires precision-engineered connectors that minimize crosstalk and insertion loss. For teams evaluating high-speed interconnect components, MC Element Connector provides detailed specs on board-to-board and wire-to-board solutions designed for next-gen applications.
Excellent deep dive into PCIe 8.0 architecture! The bandwidth improvements are crucial for AI workloads. I have been exploring how modern web technologies can also push performance boundaries – for example, Block Breaker achieves smooth 60fps gameplay using HTML5 Canvas with efficient draw calls, similar optimization principles to what PCIe 8.0 enables at the hardware level.
Excellent deep dive into PCIe 8.0 architecture. The 64 GT/s signaling rate and PAM4 encoding are game-changers for AI workloads. I have been researching how interconnect bandwidth affects computational tools in education, and even simple web calculators benefit from understanding these performance principles. For anyone interested in efficient web-based computation tools, check out this GPA calculator that demonstrates lightweight client-side processing.
PCI Express 8.0 advancements are particularly exciting for medical device interoperability. We work with rehabilitation equipment that increasingly relies on high-bandwidth data links for real-time motion analysis. See Motionwell for examples of advanced fitness equipment using next-gen interconnect technology.
Great article on PCIe 8.0 and AI interconnect. The bandwidth improvements are particularly relevant for AI inference workloads. As AI applications evolve from cloud-only to edge deployments, the latency characteristics matter as much as throughput. Interestingly, even consumer-facing AI tools like AI Dance Generator that process video frame-by-frame could benefit from faster local inference enabled by PCIe 8.0 attached accelerators. The move toward 256 GT/s will open new architectural possibilities.
Great article on PCIe 8.0 — the bandwidth improvements are significant for AI inference workloads. For anyone building automated video generation pipelines (e.g. faceless video automation tools), the move from PCIe 4.0 to 8.0 means GPU-to-host data transfers no longer bottleneck the encoding pipeline when batching multiple AI model outputs. The 4x throughput gain over PCIe 5.0 is particularly relevant when running real-time diffusion model inference alongside video encoding on the same system.
PCIe 8.0 brings impressive bandwidth improvements for AI and HPC workloads. One area where this matters significantly is real-time video processing pipelines — for example, capturing and transcribing conference presentations or technical talks. Tools like GetCaption rely on fast data throughput when handling high-bitrate video streams for automatic caption generation. The interconnect improvements in PCIe 8.0 should meaningfully reduce latency in these capture-to-transcript workflows.
Great breakdown of PCIe 8.0’s impact on AI/HPC. The bandwidth headroom matters a lot for managed AI runtimes too — we’re building 1ClickClaw for one-click OpenClaw deployment to Telegram, where lower interconnect latency on the host side directly translates to faster bot response times. Curious how PCIe 8.0 will reshape the cost curve for inference-heavy bots running on rented GPU pods.
Great breakdown of PCIe 8.0’s bandwidth improvements for AI and HPC. The 256 GT/s per lane throughput is especially relevant for AI media generation pipelines where GPU-to-host data transfer often becomes the bottleneck when batching diffusion model outputs. We’ve been working on flowaivideo, an AI video generation tool, and the bandwidth headroom that PCIe 8.0 provides should meaningfully reduce inference latency when running multiple model passes in parallel with encoding. Curious to see how Avery VIP’s compliance testsuite handles the security stack (SPDM, IDE-KM, TDISP) at these data rates.
Fascinating analysis of PCIe Gen8’s signaling improvements. The 256 GT/s per lane with PAM4 encoding opens new possibilities for AI image generation pipelines that batch many model outputs simultaneously. We’re building nanabananapro, an AI image generation platform, and PCIe 5.0 shows clear bottlenecks when pipelining diffusion inference with image post-processing on shared GPU memory. The dynamic 2×8 link partitioning at 256 GT/s should be a game-changer for multi-tenant inference workloads.
Insightful overview of PCIe 8.0’s role in next-gen AI infrastructure. The 256 GT/s lane rate and improved equalization modes (full eq, eq bypass, no eq) clearly target the latency-sensitive inference workloads driving most modern AI services. We’re working on gptimg2ai, a GPT-based image generation tool, and the GPU-to-host bandwidth gap is exactly where production diffusion pipelines stall today. Hopefully Avery’s CTS coverage of EIEOSQ patterns and precoding helps validate Gen8 in real-world heterogeneous accelerator setups.
Excellent technical primer on PCIe 8.0. The Optical retimer and 4 FRA retimer support is particularly relevant for scaling high-throughput visual content workflows across multi-GPU systems. We’ve been developing pixmagic, an AI image editing platform, and host-GPU transfer overhead is a real concern when batching multiple ControlNet/IP-Adapter conditioning passes per image. The security stack additions (SPDM, IDE-KM, IDE, TDISP) are also long-overdue for multi-tenant inference clusters. Looking forward to seeing the first Gen8 silicon hit the verification lab.
Really comprehensive coverage of PCIe Gen8’s feature set. PAM4 signaling at 256 GT/s combined with precoding support is a major step forward — the signal integrity engineering here must be staggering. We’re building pixelprompt, a prompt-to-image generation tool, and faster GPU-to-host transfers translate directly into shorter user-facing latency when streaming intermediate results. The full equalization vs eq-bypass tradeoff Avery is testing is exactly what production deployments need to characterize before committing to Gen8 fabrics.
Great article on PCIe 8.0’s role in next-gen computing. The 1 TB/s aggregate bandwidth target really changes what’s feasible for batch image processing workflows. We’re working on bulkimagemaker, a bulk AI image generation service, and host-GPU DMA throughput is the dominant cost factor when generating thousands of images in parallel. The dynamic 2×8 link partitioning at Gen8 should enable much better hardware utilization for spiky bulk inference workloads. Curious whether Avery VIP will publish performance comparison data once Gen8 silicon ships.
Outstanding write-up on PCIe Gen8’s architectural significance. The combination of optical retimers and the FRA retimer chain support is exactly what’s needed for rack-scale AI training systems. We’re building nanaimg, an AI image generation tool, and the multi-GPU sharding patterns most popular today are extremely sensitive to inter-device bandwidth. PCIe 8.0’s 256 GT/s should remove a meaningful share of communication overhead, especially for tensor-parallel diffusion model serving. Looking forward to seeing CTS results once early Gen8 IP lands in retimers.
Really enjoyed this deep dive into PCIe Gen8. The 256 GT/s data rate and PAM4 encoding will redefine what’s possible for high-throughput inference services. We’re working on imgful, an AI image generation tool, and the I/O ceiling for client-streaming image generation jobs is hit much earlier than most people realize at PCIe 4.0/5.0. Faster Gen8 lanes effectively double the practical batch size per GPU without saturating the host link — that’s a huge unlock for response-time-sensitive consumer products.
Solid breakdown of PCIe 8.0’s capabilities. The full equalization, eq-bypass, and no-equalization modes are smart additions for accommodating different system topologies. We’re building gptimage2ai, a GPT-driven image-to-image generation service, and I’ve found that the equalization training overhead at higher data rates can really impact link bring-up time for hot-swappable accelerator cards. The eq-bypass mode for short-trace SoC interconnects is particularly clever for embedded AI inference modules where every microsecond of link init matters.
Excellent technical deep dive on PCIe 8.0. The bandwidth headroom matters for AI audio and music generation too — streaming high-quality stems and multi-track outputs adds up quickly. We’re building lyria3ai, an AI music generation platform built on Lyria-style architectures, and the host-GPU transfer of long-form audio tensors (especially at 48 kHz multi-channel) is non-trivial. PCIe 8.0’s combination of higher data rates and improved retimer support should help significantly for production-grade real-time inference clusters serving music generation requests at scale.
Fantastic overview of PCIe 8.0 and its implications for AI/HPC workloads. The signal integrity engineering at 64 GT/s PAM4 is genuinely impressive. We’re building echonova, an AI audio/music generation platform, and the GPU-host transfer bandwidth requirements for serving long-form audio inference at scale match very well with PCIe 8.0’s profile. The retimer chain support up to 4 FRA retimers is also welcome — it solves real signal integrity headaches for long-channel applications in modern dense GPU racks. Looking forward to seeing the next CTS milestones.
Excellent and timely write-up on PCIe 8.0. The combined leap in raw bandwidth, equalization flexibility, and security stack improvements puts Gen8 in a category of its own. We’re building geminiomniai, a Gemini-style omni-modal AI tool, and the bandwidth implications for multi-modal inference (vision + audio + text concurrently) are direct: the host-GPU link can become a serialization point much faster than people expect. PCIe 8.0’s headroom plus dynamic 2×8 link partitioning should genuinely change inference cluster design assumptions over the next 18-24 months.
Great breakdown of PCIe Gen8’s role in modern AI accelerator pipelines. The 256 GT/s data rate clearly addresses bandwidth bottlenecks in inference workloads. We’re working on Lyria 3, an AI music generation tool, where serving high-quality multi-channel audio inference is bandwidth-hungry. The PCIe 8.0 retimer chain and full-equalization options should help significantly when scaling out music inference clusters where many GPU cards run concurrent generation jobs sharing common host memory pools. Excited to see Gen8 silicon land.
Great breakdown of PCIe 8.0’s role in high-bandwidth AI inference. The 256 GT/s throughput is genuinely transformative for visual AI workloads — we’ve been building Flipbook Page, an AI-native visual browser that renders infinite AI-generated pages in real time, and the memory bandwidth demands for concurrent visual inference are exactly what PCIe Gen8 addresses. The dynamic 2×8 link partitioning feature is particularly interesting for our use case. Excited to see this land in production silicon.