Virtual prototype assembly (VPA) for NVH prediction: from capability to process
Somebody once told me: “Ordinary People Focus on the outcome. Extraordinary people focus on the process.” Sometimes it does matter much more to learn from outcomes, be agile and adapt your process to be more successful in the future. I strongly believe the same counts even more so for organizations. A few of the most successful companies managed to not only re-invent themselves, but to set up processes that make them more successful!
Setting up an extraordinary company process
For more than 15 years now, I have been working with carmakers worldwide as an automotive NVH expert. Over those years, I have seen lots of differences in how companies are set up and organized to do NVH engineering. How to orchestrate cooperation between different development teams, either inside or outside the company, is a key challenge. How, for instance, to have different engineering teams working independently on each of the different components and systems that built up a vehicle, without losing sight of the final NVH performance of the assembled vehicle? How do you cascade targets and monitor progress while seeing how everything works together?
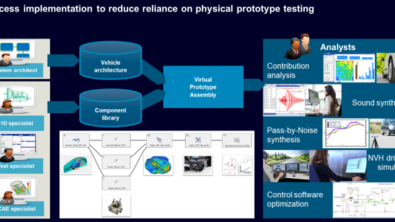
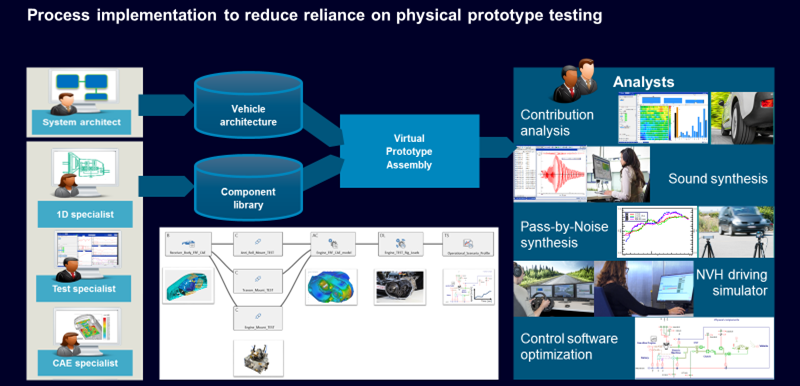
For a few years, I have been at the forefront of one of the most exciting product developments within our NVH testing portfolio at Siemens: vehicle NVH prediction enabled with Simcenter Virtual Prototype Assembly (VPA) software. With this solution, we enable carmakers to make virtual vehicle assemblies and evaluate their’ NVH performance. For me, the key is not just this capability that comes with it, but the implementation of a company-carried process that makes this solution extraordinary!
So our ambition is to set up a process, that allows NVH test or simulation engineers to create VPA components, store and share those and reuse those as basis into virtual assemblies that calculate how everything will work together to create a certain NVH performance of the vehicle. This process is not used just by a few people that go in full person through it individually, but really many different personas are part of this process. People work with people, so orchestration of the process is key to success.
I would like to talk a bit more about the management of all data streams and how different user personas can successfully make part of this.
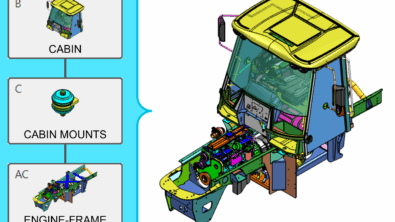
The birth of a VPA component that leads its life within the organization
In order to make this process a success, it needs maximum contribution and buy-in of all different stakeholders. This means, for instance, that experts need to be sure, that the components they create, contain all context information, relevant to the broader organization. Also, correct usage needs to be warranted to motivate experts to publish their data and to avoid making wrong conclusions on the assembly level later. This context information means, for instance:
- what type of component it is and in what type of assembly it can be used. For example, it is a source such as a specific powertrain with a specific mounting configuration, a specific tire, or a powertrain mount, …
- What version/type number does this represent? This could be a model-built number or a serial number of a physical prototype of a system being tested, …
- What operating condition/state it represents, e.g. what was the speed of the tire that was tested?
Secondly, many different test and simulation tools are often used, so it should be possible to create components, using any source of data.
All of this is covered by the VPA process when defining VPA components in the definition phase. The process goes in a few steps. First, when VPA components are created, the respective component template can be chosen. This contains all the right target naming conventions and information relevant to the type of component to be able to assemble it correctly later. The template is populated next with the relevant data. This data can be native Simcenter Testlab and Simcenter 3D or any other sources of data. Mapping tables can be set up to warrant smooth automatic conversion of point naming conventions towards target names. This is important in case other naming conventions are historically used in, for instance, CAE tools to remove risks of mistakes and also simply a lot more efficient.
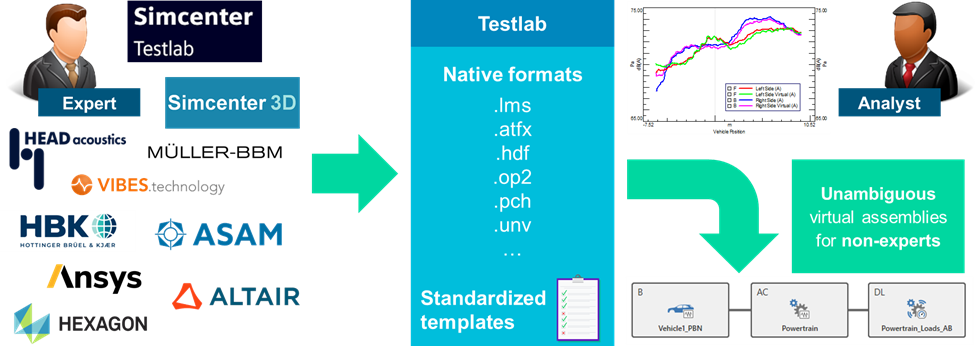
It is still insufficient. Additional customized context information can and should be further added. For this template-based descriptive information for the component, can be entered. The user is requested to enter relevant meta information before the actual publication starts. The templates can be managed, e.g. by a lab-manager. The relevant data can be chosen from a central model, preselected/default values could be set up, drop-down selection lists can be used for specific attributes, distinctions between mandatory and optional items can be made, and so on.
Now all is ready to start the new life of the component and publication can happen. This publishing can be either locally, or better, pushed into a central ASAM-ODS database. When this happens, the component will be available for the broader organization for those that have permission to access the data, and the VPA component can start leading its own life.
When implementing this process within the company, this publication will become common practice. Whenever milestone versions of components and systems under development are reached, they will be published to the benefit of many.

Usage of shared component data in virtual assemblies across the company
The longer the VPA process is in place, the richer the library of components becomes. This creates the risk however to get lost in the vast amount of data. Also, this part of the process is properly thought through to avoid getting lost.
As all components are stored centrally in the ASAM-ODS database, which does not only contain the data, but also the central index database containing all metadata. Search criteria can be created and (re)used to easily retrieve the component data and all of this directly from within the actual VPA software.
The example below shows how search criteria are created to retrieve CAE-based body components from the central database and used in within a vehicle assembly. The simple example here, makes a virtual assembly to predict the airborne noise of an electric drive unit, integrated into two different vehicle body variants.
The virtual assemblies itself can be used will be used to simulate the vehicle NVH performance, such as interior noise performance for road or powertrain noise, the noise of small auxiliaries such as compressors but also exterior noise could be analyzed.
And what comes next?
Having this rich central database of VPA components, with all context information, is of capital value for carmakers. Even more so, because it allows starting dreaming of many other process extensions. Imagine what potential possibilities it could bring, such as:
- automatic assembly explorations combining different potential component explorations,
- automatic calculation of the NVH performance of the latest status of a vehicle under development, using the latest versions of published components,
- sensitivity analysis exercises, with e.g. parametric models used within the assembly
- …
However, the key to all this is the creation of fully documented component data in a central company database. And all of this is thanks to an extraordinary process.