Big Data for Verification – Inspiration from Large Language Models

How well do large language models work?
ChatGPT, one of the most prominent Large Language Models (LLMs), has proven it is capable of human-level knowledge by passing multiple exams with faded colors: Warton’s MBA exam with a B, the US Medical Licensing Exam at the threshold, and four law school courses at the University of Minnesota with a C+. Individually, they are definitely not the best an excellent professional can achieve, but still are a good demonstration of LLMs’ strengths of appearing universally knowledgeable.
Naturally, like many in the semiconductor industry, I was curious to check the power of ChatGPT on IC design. When asked to design a traffic light controller in Verilog, I was presented with an almost perfect code example accompanied by clear explanations. However, when asked to design a 5-way traffic light controller, ChatGPT showed me a design with 5-color traffic lights: red, green, yellow, blue, and purple. How I wish to witness such a traffic light in the real world! Obviously, ChatGPT has undergone several revisions by OpenAI, and the alien world traffic controller has recently been replaced by a more reasonable design.
Others have shared similar encounters with ChatGPT. Some believe that it’s not yet ready for production applications. Such conclusions totally miss the point. While average human performance at most cognitive tasks stays relatively stable, ML systems can ingest training data and become smarter at exponential speed, with the help of more available training data, better ML models, and advanced ML chips. An illustration by OurWorldinData has clearly demonstrated these trends — ML is getting better and faster at catching up with human performance in more and more tasks.
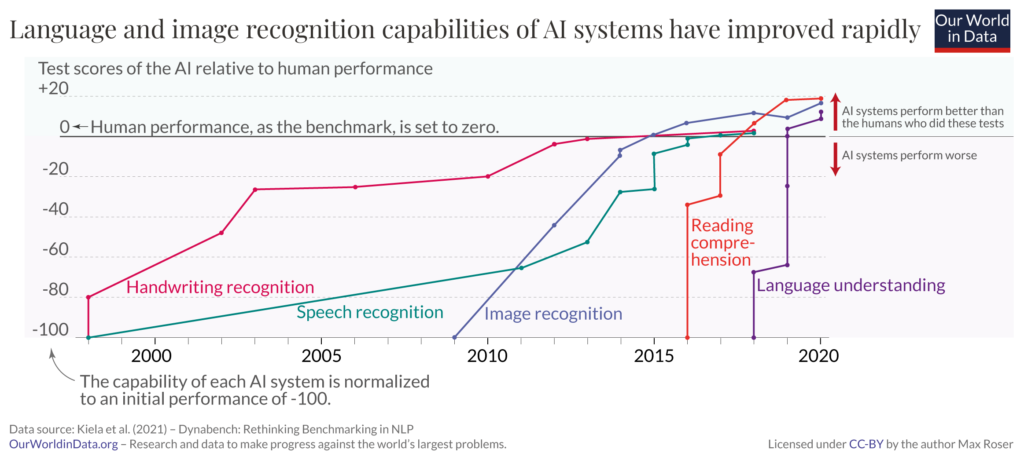
The same is being witnessed by my traffic controller test to ChatGPT. I have observed its improvement over time, although sometimes it still gives out-of-line answers.
One would be curious to ask, how does ChatGPT become so knowledgeable? Returning to the fundamentals of ML would shed some light on the answer to this question.
3 Key factors of an ML system
An ML system needs 3 important factors to run: training data, an ML model, and computing power. Data is arguably the most important.
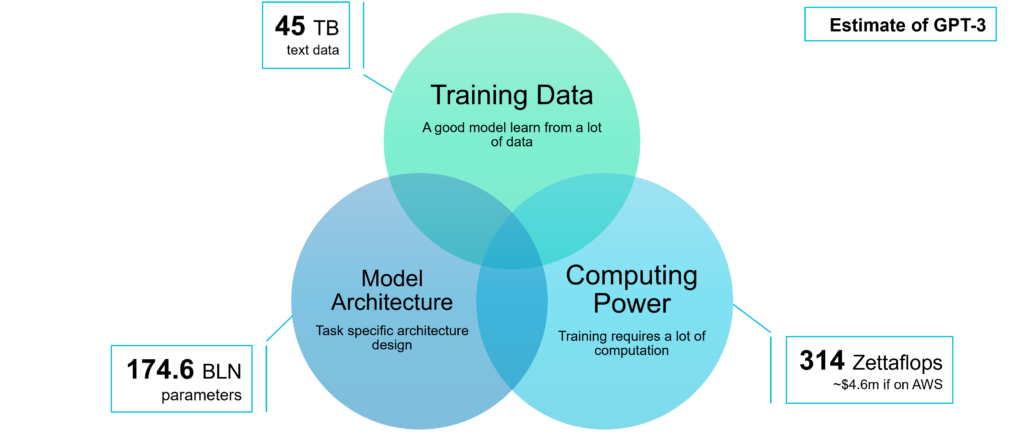
Although the details are still murky, from disclosed information about GPT-3.5 that ChatGPT is based on, and its predecessor GPT-3. We can still peek behind the curtain and gain some insights into how these 3 factors contribute to ChatGPT’s capability.
The information regarding ML models used by ChatGPT is relatively transparent. It has been mentioned by OpenAI in their blog and several earlier publications. Indeed some open-source LLMs have demonstrated performance similar to GPT-3, and their source code and model weights are both readily available to download.
The cost of training GPT-3 is estimated to be about $4.5 million, and will only be higher for ChatGPT for its additional reinforcement learning training. Such kinds of training would naturally demand very powerful GPU clusters. It is no secret that few can afford the computing power to train ChatGPT, which is the natural barrier to many aspiring competitors. Still, many big players can afford the cost and are racing to make similar offerings.
GPT-3 is trained on about 45 TB of textual data, and GPT-3.5 very likely may have more training data. The textual data from internet crawling, books and internet forums, code repositories, and Wikipedia are mostly openly available for anybody to download and train their model. By learning from many web pages, books, and discussions about EDA, ChatGPT has also inadvertently acquired the knowledge to answer EDA questions.
What really separates ChatGPT from other competitors is its possession of additional high-quality data. Besides filtering and curating the acquired data to improve the quality, OpenAI is reported to have hired an army of contractors to annotate the data to help elevate the quality of their models’ output. And they are still continuously updating the data by even learning from user interactions. By focusing on data, OpenAI, the company behind ChatGPT, is able to leap ahead of competitors.
State of ML applications in verification
Many have realized that verification is ultimately a data problem. However, applying ML to verification has never been easy.
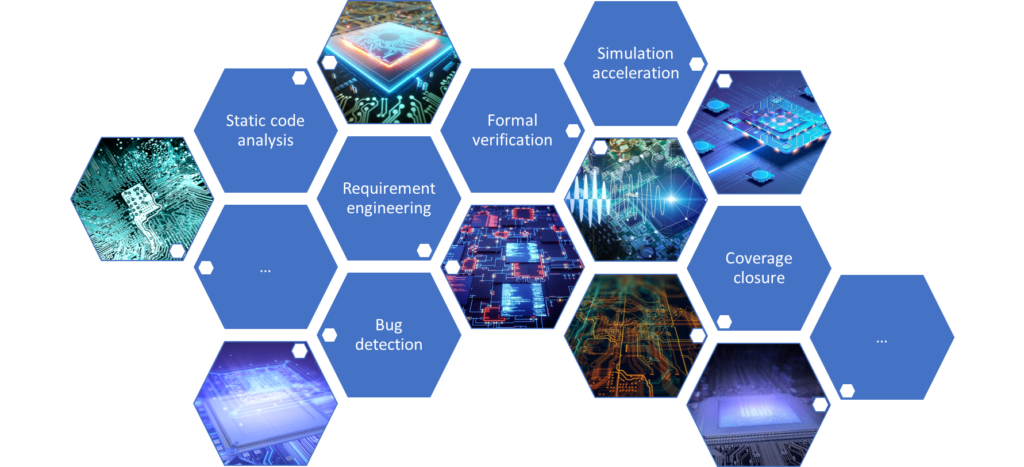
In a DVConUS 2023 paper titled A Survey of Machine Learning Applications in Functional Verification, we surveyed ML applications in verification and discovered that ML can be and has been experimented with in almost every field of functional verification. Many existing research papers have demonstrated encouraging results in requirement engineering, static code analysis, verification acceleration, coverage closure, and bug detection/localization. ML has been proven to be capable of accelerating the verification process, improving the verification quality, and automating verification execution.
However, a deeper look into those research results also revealed that most of these published results only used relatively primitive ML models in their study, with very few adopting deep learning techniques. Some may attribute this to the researchers’ lack of advanced ML skills, which is actually not the case. Many of those papers were published in the last few years when deep learning libraries and techniques were already readily available.
The real reason is that most researchers only have access to very limited verification data. They either have to spend a major portion of their precious research time on data preparation or have to settle with publically available but very limited datasets and manually enrich them with verification data. Either way, without sufficient training data, many data-hungry advanced ML models simply are not applicable.
Verification data platform
The problem of unavailability of verification data does not only slow down the research of advanced ML in verification. The design IPs and the associated verification data, including the verification plan, simulation settings, assertions, regression results, simulation logs, coverage data, trace files, revisions, and their commits, are arguably the most valuable assets in most semiconductor companies. These valuable data assets have hardly been accessible in the past. They are either siloed among different team members or projects or simply discarded due to the lack of analytic techniques to extract value from them.
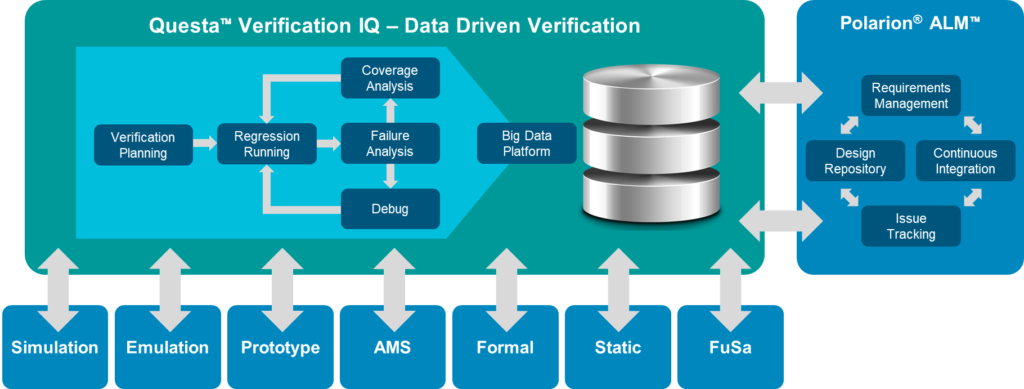
The Questa Verification IQ (VIQ) product announced last month aims to change the situation by providing a unified data platform. It enables data analytics and advanced techniques like ML to gain insights into the verification process, empowers collaboration between team members to have a holistic view and unified data access, and provides transparency in verification requirement traceability. In the upcoming DVConUS, Siemens will be presenting a tutorial, Evolutionary and Revolutionary Innovation for Effective Verification Management & Closure, that will discuss the powerful tools provided by the VIQ verification platform to extract value from the verification data. In the tutorial, we will also present examples of how ML can enable verification teams to make verification faster, more accurate, and more automated. The tutorial will be on Thursday, March 2nd, the last day of the conference. We hope to see you there. But even if you haven’t registered for the tutorial, be sure to drop by our booth and have a look at how consolidating verification data will help every verification researcher and engineer achieve their goals.

