Decoding LLM Hallucinations: Insights and Taming them for EDA Applications

In an earlier blog, I explained that LLM will learn much faster than humans and there are many possible applications in verification. Two months later, the latest iteration of ChatGPT has been passing many harder exams with flying colors. This has ignited many people’s interest in applying LLMs in more domains including EDA. However, the immediate future may not be as rosy as we might have thought.
One of LLMs’ biggest weaknesses is hallucination, exemplified by two lawyers who copied hallucinated bogus cases directly from ChatGPT without fact-checking and a defamation suit over a non-existent embezzlement complaint generated by ChatGPT.
LLMs will still take time to replace EDA engineers. Hallucination and many intrinsic limitations will put them firmly into the assistant seat until a fundamental change in how LLMs work.
Universal Approximation Theorem and Its Implication
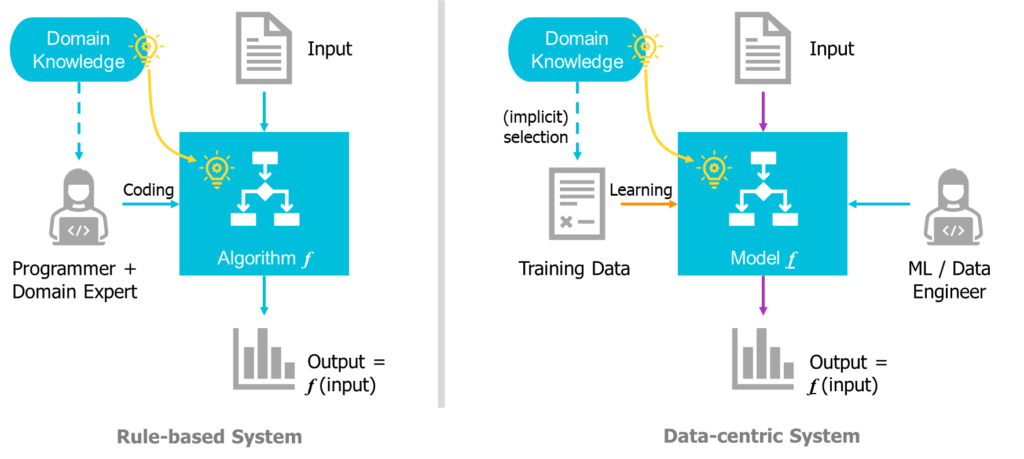
To better understand how an LLM works, we’ll have to trace back to the general ML’s working mechanism. In a rule-based system, the knowledge is learned by the domain experts, summarized into explicit and explainable rules, then coded by a programmer into an executable algorithm. This is in sharp contrast with data-centric systems. Like the supervised ML system in the figure, they exploit the intrinsic structure of the training data to implicitly learn the rules from the training data and automatically build the model to approximate the target function.
The Universal Approximation (UA) Theorem has proven that an Artificial Neural Network (ANN) can approximate the behavior of any continuous function in a certain range at arbitrary accuracy. The proof for the recurrent neural network (RNN) was given by our Siemens friends Anton Maximilian Schäfer et al. in 2006 [1]. The UA theorem has multiple implications:
- An ANN can only approximate a given function: Except for a few very special cases, most ANNs will only be Good Enough TM approximations of their respective target functions.
- It can only do so within a given input range: it is undefined what will happen to the out-of-range cases.
- The target function shall be continuous: In most cases, we don’t even know if the target function is continuous, and we may only obtain very limited samples from the problem space.
UA’s Implications to LLMs
Do the implications listed above apply to LLMs? The answer is also a definitive yes. The proof for the transformer (a special ANN architecture serving as the foundation of all LLMs) was given in a paper titled “Are Transformers universal approximators of sequence-to-sequence functions?” [2] What does it mean to apply LLMs to solve EDA problems?
An LLM’s answer can only be regarded as an approximation. Depending on the model performance, it shall not be regarded as the accurate or optimal answer. Especially when the employed training data might be intrinsically inaccurate, or less optimal like scraped or crowd-sourced data used to train these LLMs. It may work for some natural language problems, but such behaviors are not desired when precision and rigor are highly valued. Just as LLMs can still make grammatical mistakes, they tend to make more mistakes in solving EDA problems.
For any answer that is out-of-range of the training data of an LLM, the result will be unpredictable. In the cases where the training samples are dense, and the model is well trained, the results may be reasonable — but there is no guarantee. The story of the 5-color traffic controller design in Verilog in the last blog is just one of many examples some LLMs may give outlandish and unexpected answers to some out-of-range prompts.
Most real-world problem spaces are very likely discontinuous. Many ML models work well for their respective problems because the low quality answers can be tolerated or the problem spaces are near-continuous. However, this is not the case for natural languages or programming languages. Most natural languages are highly irregular and ambiguous. For natural languages, look at many forms of irregular inflections of English verbs. While programming languages may have well-defined simple grammar, their implementation complexity is still highly discontinuous. For example, we may initialize two variables with 2 assignment statements, but we rarely do it for 100 variables’ initialization.
Hallucination of LLMs in EDA
Analyzing the UA’s implications will help us better understand the restrictions of LLMs, and therefore helps better apply them in EDA.
Hallucination because data in EDA are sparse. As of mid-2022, our survey indicates there are about 10m lines of code and documents in 40 thousand HDL projects hosted on GitHub, RISC-V and OpenCores, regardless of their licenses. But it is easily dwarfed by the scale of other popular programming languages, like JavaScript, Java, or Python with 6.8m, 5.7m, and 3.5m projects respectively [3]. With sparse samples, these LLMs’ performance on HDL is expected to be less ideal than most popular programming languages. It can be remedied to a certain extent because many programming languages may share similar concepts learned from natural languages or other programming languages.
Hallucination due to (lack of ) data quality. Quality data are not easily accessible. Despite open-source data availability, most large-scale and highest-quality data are still confined in their individual silos. They probably will never be available to train a generally useable LLM. We are cautiously optimistic that the situation may improve over time when more and more quality designs are made available by the community and generous contributors. The rise of RISC-V may further catalyze and accelerate this openness process.
Hallucination when the task is out of range. Unprepared users may be surprised by LLMs pretentious answers about some non-existent people and their publications. It happens when the question is beyond the scope of datasets used for training. It can be remedied by grounding the answers to the actual data in the datasets. The trained model will give a higher rank to the answers with a real reference instead of the pretentious ones. The most recent update of the ChatGPT model tries to provide references with more real sources behind them if you ask. Many of these references may be less relevant to the questions, but at least they do exist.
Hallucination happens when an LLM doesn’t fit well. It was estimated that training of GPT-3 would cost millions of dollars. While it was never disclosed, training of GPT-4 would be in the tens of millions of dollars range. Training an LLM used to be so expensive that many LLMs are reported to be undertrained. The situation is rapidly changing with the help of newer-generation GPUs and specialized accelerators for LLMs. The arrival of finetuning techniques like LoRA has also made it possible to finetune a model at more affordable cost. The new models are expected to be better trained and fit the data better than their predecessors.
Outlook
Although hallucination is a new term coined for generative ML models, it shares many common traits with other ANN models. Due to the UA theorem implication, hallucination will never be entirely eliminated from LLMs if they’re still based on neural network models. We’ll have to live with hallucination and find creative ways to alleviate its undesired impacts on the applications.
Besides the countermeasures discussed above, the results generated by LLMs must still be carefully inspected and verified by their users and/or proven methodologies. Various control mechanisms must be imposed to maximize the productivity boost brought forward by LLMs to meet ever-higher precision and rigor requirements in EDA.
The data-driven verification methodology promoted by Questa verification products helps our users focus on gathering verification data from the entire verification cycle and extracting value from the data. Once many high-quality data are available, a well-trained LLM will prove to be more robust with less tendency to hallucinate.
If history teaches us anything, a revolutionary event’s short-term impacts tend to be overestimated, while its long-term impacts tend to be underestimated. It seems the invention of LLMs might be such an event. At Siemens, we still firmly believe in bringing value to our users, and LLMs will serve as invaluable assistants to the productivity boost. At the same time, their pitfalls will be carefully guarded by Siemens’ rigorous verification technologies.
[1] Anton Maximilian Schäfer, Hans Georg Zimmermann. “Recurrent neural networks are universal approximators.” Artificial Neural Networks–ICANN 2006: 16th International Conference, Athens, Greece, September 10-14, 2006. Proceedings, Part I 16. Springer Berlin Heidelberg, 2006.
[2] Chulhee Yun, Srinadh Bhojanapalli, Ankit Singh Rawat, Sashank J. Reddi, Sanjiv Kumar. “Are transformers universal approximators of sequence-to-sequence functions?.” arXiv preprint arXiv:1912.10077 (2019).
[3] Dan Yu, Harry Foster, Siemens EDA; Tom Fitzpatrick. “A Survey of Machine Learning Applications in Functional Verification.” DVCon 2023
Update Jun 19, 2023: My colleague Mark Hampton pointed out that I have an hallucination. As of now ChatGPT does not provide links to sources yet, unless you explicitly ask for them.


