The crucial role of data management in achieving success
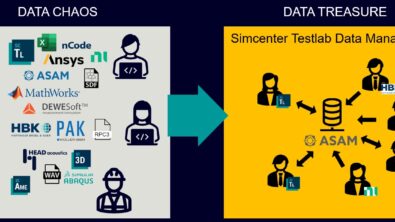
In today’s business landscape, the importance of data management cannot be overstated. Many large companies possess a wealth of valuable engineering data accumulated over the years. This data is akin to gold, universally recognized as a precious resource.

However, the challenge lies in unlocking the true value of this stored treasure and harnessing it for the benefit of the company.
Traditionally, this valuable data is stored on various devices such as hard drives, employee PCs, or, at best, centralized network drives. While the safekeeping of this data is crucial, the true test lies in effectively utilizing it to drive organizational success. This is where the journey begins.
In the world of NVH engineering, companies struggle to utilize historic data effectively due to various challenges:
- Sleeping data on local drives or PCs poses a risk of loss when employees leave or are absent.
- Diverse file formats make it difficult to interact with and search through the data.
- Data is often stored without clear context, making it challenging to find the required information.
- Comparing data involves opening and closing multiple files with specific naming conventions.
These inefficiencies and risks hinder progress and compromise the organization’s future success. Proper data management is crucial, as it lays the foundation for implementing essential technologies like AI in vehicle development
How to address all those obstacles and get ready to take the next step? Continue reading to get an understanding of how it is being done
Towards a central database
Simcenter Testlab Data Management revolutionizes the way NVH data is handled by transitioning from a file-based, often local, approach to a centralized database adhering to the ASAM ODS NVH standard. This concept applies not only to original Simcenter Testlab datafiles but also to various other data types such as hfd, wav, uff, and more, making it the go-to database for all NVH data sources.
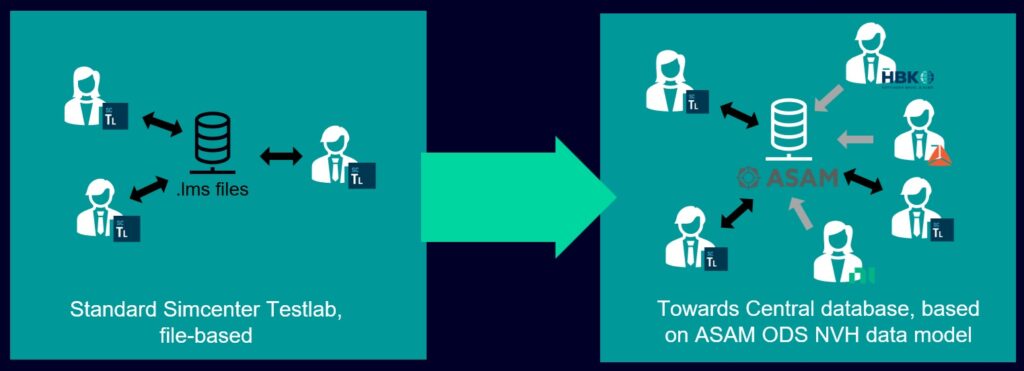
From local data files to a central ASAM ODS database
The key advantage lies in managing crucial data-context information within the database, including data type (time, frequency, resolution, function types, etc.) and company-specific annotations (test engineer, vehicle condition, vehicle configuration, etc.). By consolidating this metadata, users can easily retrieve desired data by simply searching across the database, eliminating the need to search through the actual data itself.
Our data management solution aims to guide organizations towards a centralized database that offers both consistent data annotation and the actual data. The primary goal is to facilitate effortless and rapid data searching while enabling seamless data comparisons. With this streamlined approach, organizations can optimize their NVH data management processes, enhancing efficiency and driving better decision-making.
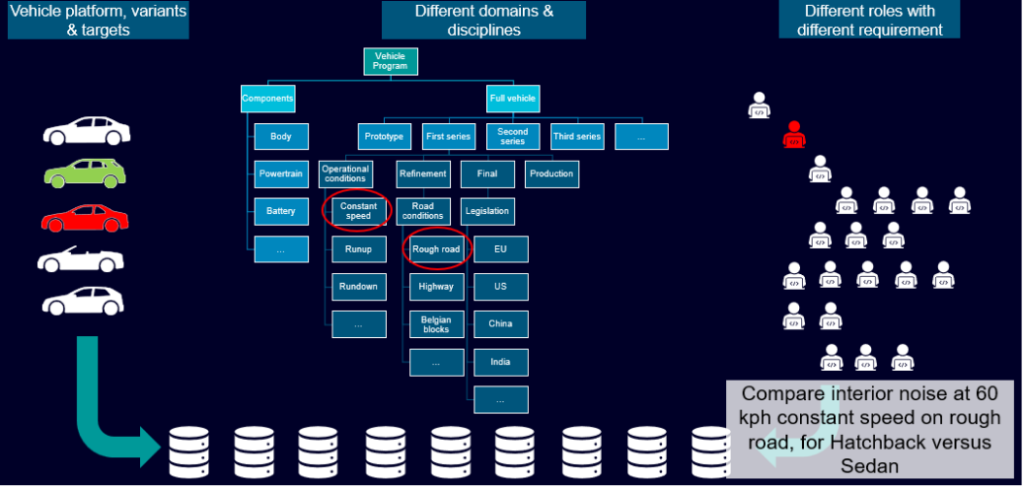
Thanks to the consistent annotation of stored data, retrieving data for A-B comparisons has never been easier.
Getting towards annotated data
Achieving a fully annotated central database may seem like an illusion, as its success relies on engineers’ willingness to annotate the data before publication. However, at Siemens, we understand that data annotation can be a time-consuming task that engineers may not necessarily enjoy. That is why we have developed a process to make the annotation process as painless as possible. The key is allowing engineers to annotate the data at the right moment in time, from test preparation to acquisition and reporting.
For example, when planning a test campaign, a massive portion of the required annotation is already known at the start of the measurement, such as the vehicle and its configuration, serial numbers, prototype variants, and more. This information can be set up in advance, with approximately 90% of the known information already filled in. This creates an annotation template file (in .ldt or Leuven Descriptive Template format) that can be used throughout the entire test. The advantage is that engineers can be certain of this information from the beginning, streamlining the annotation process.

Complete a large amount of annotation prior to any measurement that’s been done
In the next phase, when the tests are initiated, engineers can complete the annotation for each measurement further. They will be invited to add parameters specific to the test itself, such as measurement speed, that are not included in the initial annotation.

Further complete annotation during testing with test-specific items
With each measurement run, an annotation file (ldi) is generated as a result, along with the actual data. It remains flexible and can be further completed with any remaining information or corrected if necessary, during postprocessing or further analysis.
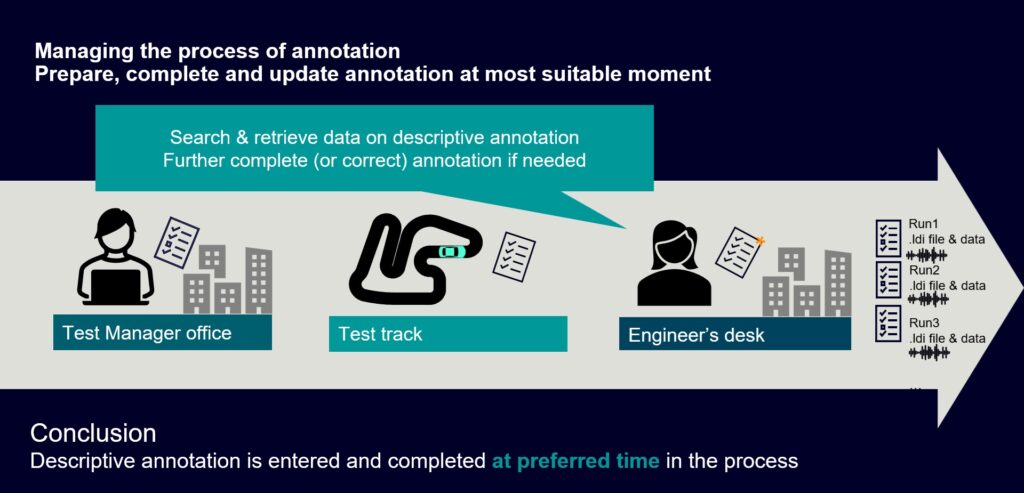
Further complete or correct annotation after measurements or post-processing
The video below demonstrates how previously measured data is accessed and reviewed in Simcenter Testlab, utilizing the annotation concept. A mistake in the descriptive annotation is detected, but it is easily corrected and completed within the system. Annotations are seamlessly available in various Simcenter Testlab concepts, such as the pivot table and legend, and any changes made are automatically updated throughout the application.
In summary, with this data annotation concept, engineers can enter and complete the descriptive annotation at their preferred time in the process. While it will still require discipline from the organization, our ambition is to achieve fully annotated data from measurements before any publication takes place in the central database.
Towards centrally published data
In the video below, you see the process of importing and annotating data in Simcenter Testlab, including both Simcenter Testlab data and other file formats. Once the data is annotated, it can be published. The video highlights an example of importing an HDF data file, adding annotations, and then publishing the entire Test section to the central server. The status of the publication can be monitored using the publish history tool.
After the publication is complete, it is possible to manually browse the data on the central server. However, it is important to note that this manual browsing is not the recommended method for users to interact with the data. It is only shown as a demonstration that the data is successfully stored on the central server.
Next, we will explore the superior method of retrieving data using the searching capabilities within Testlab. This eliminates the need for extensive manual browsing through folders, providing a more efficient way to access the desired data.
Searching data from a central database
The interaction with the central server occurs directly within Simcenter Testlab, providing users with access to all the extensive functionality offered by it while working with central data instead of local data.
One significant advantage is that data can be visualized in real-time through streaming in the displays without the need to download the actual data. This allows users to work with and analyze the data efficiently without any unnecessary delays or storage concerns.
In the video below, we demonstrate how to retrieve data from the central server in Simcenter Testlab. Searching by querying using annotations is the recommended method for retrieving data, as all data is stored fully annotated.
We begin by showing an example where we search for measurement runs conducted on different vehicle bodies and tire sets. We create a search folder and add the relevant field attributes to retrieve the desired data.
Next, we highlight another search example. The search results are in the respective search folder and displayed in a pivot table. The central data can be previewed in Simcenter Testlab by clicking on the rows in the pivot table.
If further data processing is required, the user can download the selected runs and perform additional processing using the process designer in Simcenter Testlab. At this stage, the post-processed data remains local. Although not shown in the video, it is possible to republish the post-processed data on the central server if needed.
We have demonstrated one method of visualizing data using the preview functionality. Another approach is to manually drag and drop the data into displays. However, a powerful way is to create Query-based Simcenter Testlab Reports. In the last part of the video, we show an example of opening a report that contains predefined queries, which determine what data is displayed. The queries can be interactively modified to update the data in the display. We illustrate scrolling through a specific attribute value (vehicle speed) and demonstrate how to modify the query, such as switching the DOF ID from the left headset microphone to the right headset microphone. The display automatically updates with the new data.
These Testlab Reports are interactive, and it is easy to imagine that opening a report in the future may offer more query possibilities as additional data becomes available on the central server.
The foundation for implementing essential technologies
If you are still not convinced of the value of Simcenter Testlab Data management and have concerns about the effort and discipline required from engineers, understanding its crucial role in enabling the implementation of new development technologies within your organization will change your perspective. One such technology is machine learning.
Imagine if all the NVH data in your company is properly annotated and stored in our central data management solution. This data can then be utilized to develop algorithms for artificial intelligence (AI) applications, followed by a training process of neural networks. Here are a few examples of how machine learning can be applied:
- Training an algorithm to detect low-quality data based on a large amount of historic data, including annotations indicating data quality. In some cases, additional erroneous datasets may be included to speed up the training process.
- Training an AI network to predict NVH performance after modifications or explorations with components. This can provide guidelines on which vehicle assembly variants would be beneficial or not. To achieve this, historical data with proper documentation of the different vehicle components used in the vehicles is necessary.
- Developing an AI network to replace expert expertise, such as Sound Quality evaluation, by developing an annoyance metric.
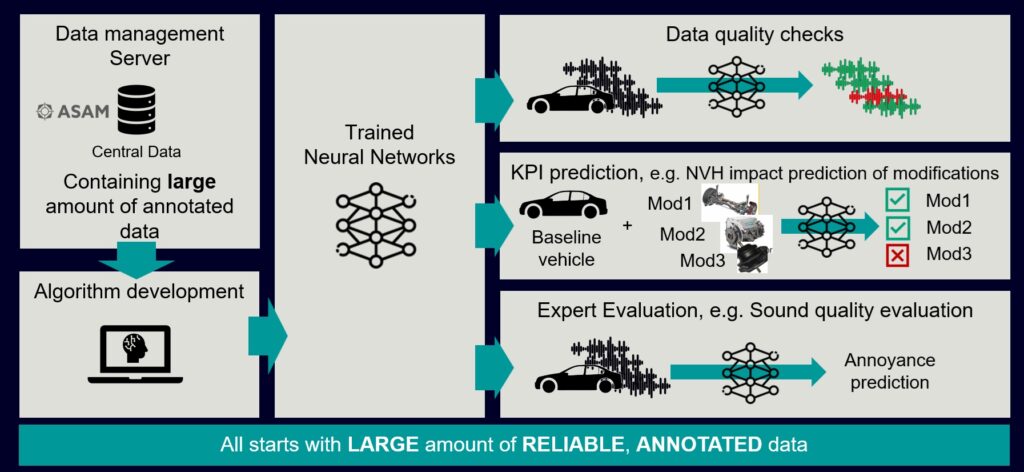
Examples of applications where AI is used in NVH engineering processes
All these applications rely on a large amount of reliable and annotated data as a starting point. Simcenter Testlab Data management serves as the crucial building block for these technologies, facilitating the efficient utilization of machine learning in your organization.
With all this, I hope to have inspired you to “open that safe of golden data” and take it to the next level to help you and your company capitalize on its value. Only by effectively managing NVH data can companies streamline operations, enhance decision-making, and pave the way for technological advancements.


