Webinar – Optimize manycore AI and ML designs

Turn complexity into a competitive advantage by harnessing system-level data to optimize manycore AI and ML chips.
Our new on-demand webinar, “Optimizing complex AI and ML SoCs: the role of system-level data”, gives you an introduction to the challenges of optimizing manycore AI and ML chips, then continues into a deeper dive on the details of the Embedded Analytics technology.
The rise of massively parallel computing has led to an explosion of silicon complexity, driven by the need to process data for artificial intelligence (AI) and machine learning (ML) applications. This complexity is seen in designs like the Cerebras Wafer Scale Engine, a tiled manycore, multiple wafer die with a transistor count into the trillions and nearly a million compute cores.
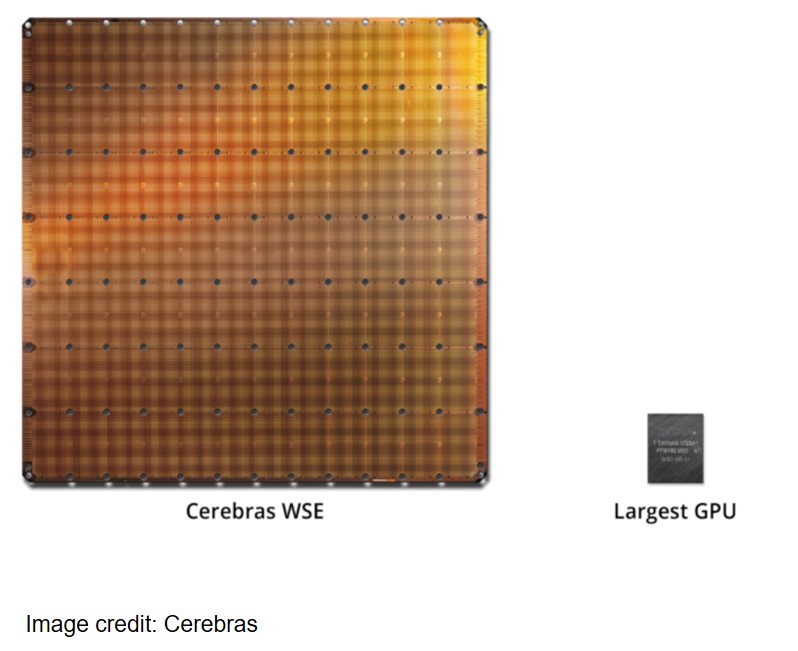
The market for AI SoCs continues to grow and is highly competitive. Semiconductor companies find their niche based on performance, cost, and flexibility. Targeting one or another of these parameters has led to an explosion of new manycore architectures. System architects are trying many different approaches, but all the designs are highly complex and all the chip makers want to harness that complexity into competitive advantage.
Of all the sources of complexity, one in particular is very important to consider in multicore AI SoCs: functional errors and degraded performance arise when many threads are running in parallel on shared data. Traditionally, designers could use classical CPU run control to debug the problem, but not with manycore architectures. Between the round-trip delay, the number of cores, control and data parallelism, multiple levels of hierarchy, and interdepended processes, designers has a slim chance of determining the root cause of the software problem.
Additionally, designers need to consider hardware-software co-optimization, which requires a lot of functional analysis. To implement AI applications on the SoC, designers need to compile the source code to take advantage of the manycore architecture. This requires a custom toolchain that has full knowledge of the architecture. The process involves a cycle of HW and SW optimization and testing starting in SoC emulation and continuing through test chip and the following generations of silicon. Through this cycle of functional analysis, the teams can learn:
- How effectively data is shared
- Whether the network on chip (NoC) is over-subscribed or unbalanced
- How to measure application performance without impacting code execution
- How to optimize the memory controller profile for data throughput
- How to correlate events from across the SoC
But getting to this point requires a new approach to optimizing AI SoCs and the software that runs on them. It calls for a system-wide function analysis to bring high-quality AI SoCs to market on time and to maintain optimal performance after deployment.
Some features of system-wide functional analysis include:
- Detailed insights into any subsystem or component
- An accurate and coherent picture of the whole system from boot
- Transaction-aware interconnect monitoring and statistics
- Classical processor run control and trace
- Support for all common ISAs and interconnect protocols
- Flexibility to choose or change which subsystems are important
- Flexible and powerful tools to generate data insights
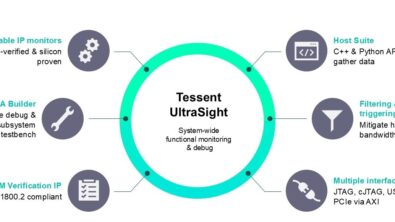
The Tessent Embedded Analytics platform of IP and software provides all this in a unique functional analysis solution. Embedded Analytics goes far beyond monitoring of on-chip process parameters to provide full system-level visibility that enables optimization throughout the lifecycle of the device.
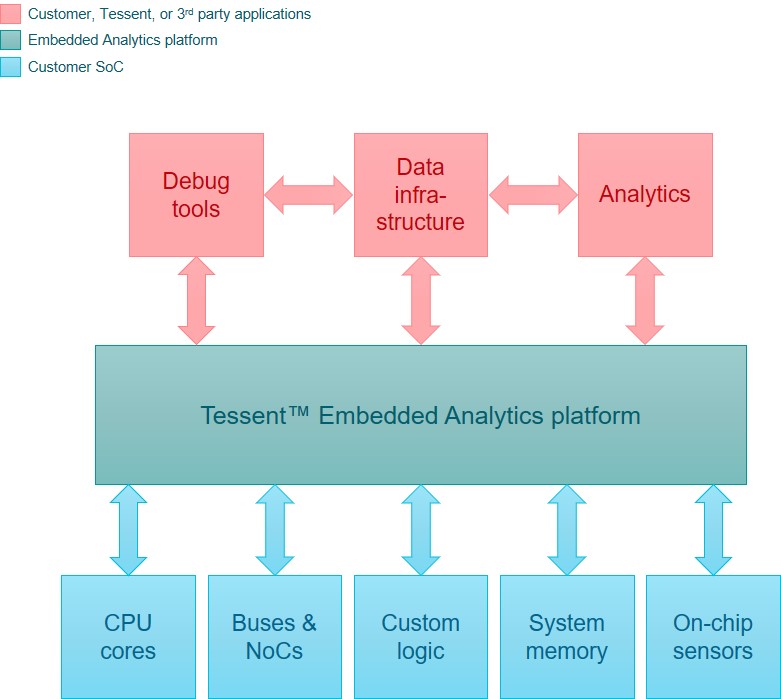
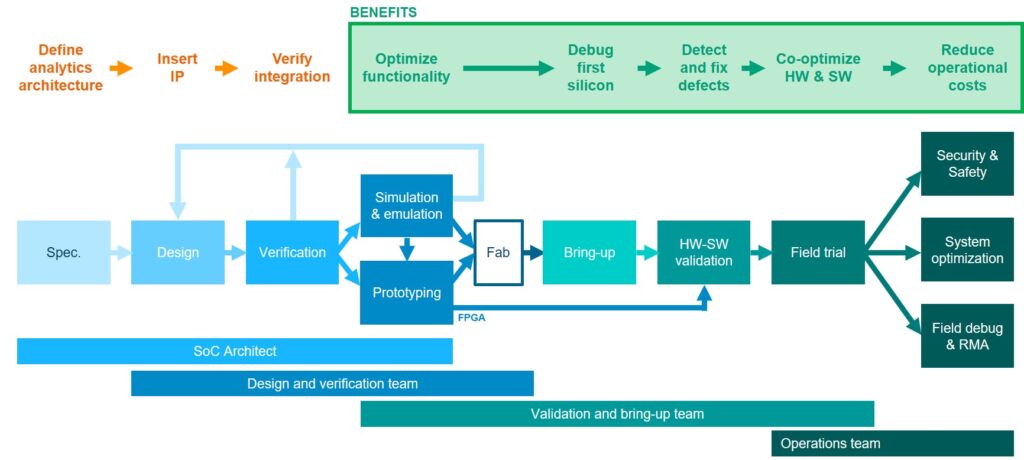
The Embedded Analytics solution provides benefits from simulation to deployment. Figure 3 shows a typical SoC lifecycle from specification to deployment and the different teams involved. Tessent Embedded Analytics is considered from the very beginning, in the architectural phase. Once inserted and verified, the SoC teams can take advantage of the system-level functional data visibility through the rest of the design and through to the real-world operation of the device.
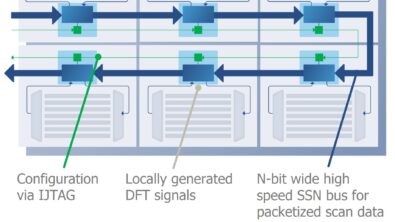
If you are ready for a deeper dive into the details of the Embedded Analytics solution, tune in to this new on-demand webinar, “Optimizing complex AI and ML SoCs: the role of system-level data.” First, product manager Richard Oxland will give you the overview and introduction, then Siemens Fellow Gajinder Panesar will show how Embedded Analytics IP blocks, like the Bus Monitor, are implemented and how they work. Panesar presents examples of manycore system-level monitoring – how it’s implemented, how all the monitoring IP uses a dedicated communications fabric, and exactly what chip behaviors can be studied.
Related resources:
Similar information is explored in our new technical paper, “Harness system-level data to optimize manycore AI and ML chips”, available to download here:
Harness system-level data to optimize manycore AI and ML chips | Siemens Digital Industries Software