Seven Ways in Which Artificial Intelligence Will Change Engineering Forever

The most misunderstood component of the engineering discipline is how the best engineers are shaped by accumulated knowledge. As engineers, we all leave university packed full of theoretical knowledge that is worth little until it is tempered with experience. That experience might take years or even decades of professional practice.
I have written about this before, how it takes a combination of “cross-pollination” and “repeated failure” before one can truly acquire “gnarly engineer” status. One of the reasons that the rate of innovation in engineering is accelerating – modern engineers have the tools to make their mistakes more quickly than ever before and hopefully learn from them.
In this blog, I want to explore how engineers are beginning to use machine learning and artificial intelligence to amplify an individual engineer’s knowledge, increase the amount of learning provided through simulation and test, and how that accumulated knowledge can be transferred between projects. I also want to dispel some myths about AI and ML and demonstrate that deploying these techniques offers a significant advantage against any of your competitors who do not use them. While I’ve previously talked about how Artificial Intelligence will influence the engineer of the future, the truth is that it is already benefitting engineers today.
1. Interpretation of Results
Engineering simulation and test routinely provide a vast amount of data. Although it is usually possible to reduce this information to a few defining parameters that describe the performance of a design, experienced engineers acquire the ability to visually interpret these vast data sets (often data-rich three-dimensional fields that vary with time). This allows us to identify critical features – a vortex or a separation bubble in flow simulations or a stress concentration of temperature gradient – that directly influence the performance of a design.
It is common for design teams to use large teams of less experienced (and therefore less expensive) engineers to do most of the heavy lifting in a simulation (meshing, setting up problems, running the calculations and post-processing the results) or test (actually performing the experiments). More senior (and better paid) engineers then review the results and make the decisions.
The problem is that the three-dimensional results fields contain lots of useful information. And while it might be convenient to reduce the performance of a design to a few key parameters optimizing over a limited parameter set might tell you which designs are performing better than others. Still, it will not necessarily tell you why they are performing better.
To address this, Simcenter customers are now using machine learning to scan the results of thousands of previous simulations and train an algorithm to identify those flow features (or stress concentrations or whatever) that have the most significant influence on the performance of their product. More impressive is that those defining features are not always things that even the most experienced engineer might spot, increasing the value of simulation’s data.
2. Speed of Simulation
The speed of engineering innovation is always limited by the availability of resources, which usually means either a lack of engineering resources or computer processing power.
Identifying individual components from a mass of interconnected parts in a CAD assembly can be an intensely time-consuming manual process. Unfortunately, this step is unavoidable if you want to define local meshing properties, or a physics boundary condition, or so that a part can be identified as part of a post-processing report.

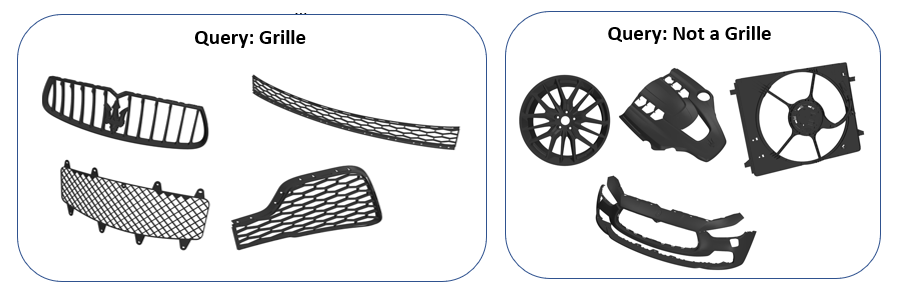
For example, in an aerodynamic underhood simulation, a radiator grill is treated differently than a rotating alloy wheel. Using machine learning from previously categorized simulation models, AI (Artificial Intelligence) can be trained to identify individual CAD components from a combination of their shape and metadata appended to the part.
3. Instantaneous Insight
As engineers, our job is to answer the “what if?” questions that drive the engineering design process. All of us have experienced the frustration of arriving at a design review meeting with a presentation full of simulation and test results, only to have someone ask the question, “what about if we just tried this?” where “this” is the one scenario you had not previously considered. In the past, you would have had to trudge back to your desk to begin the time-consuming process of rerunning a batch of simulations to fill those gaps.
In this case, machine learning algorithms can accumulate knowledge from previous simulations and instantly predict the outcome of the design changes, including full three-dimensional scalar and vector fields. This allows engineers to see the probable outcome of their speculation in real-time. If the training database is sufficient, the difference between the AI-predicted values and the actual simulation results can be insignificant.
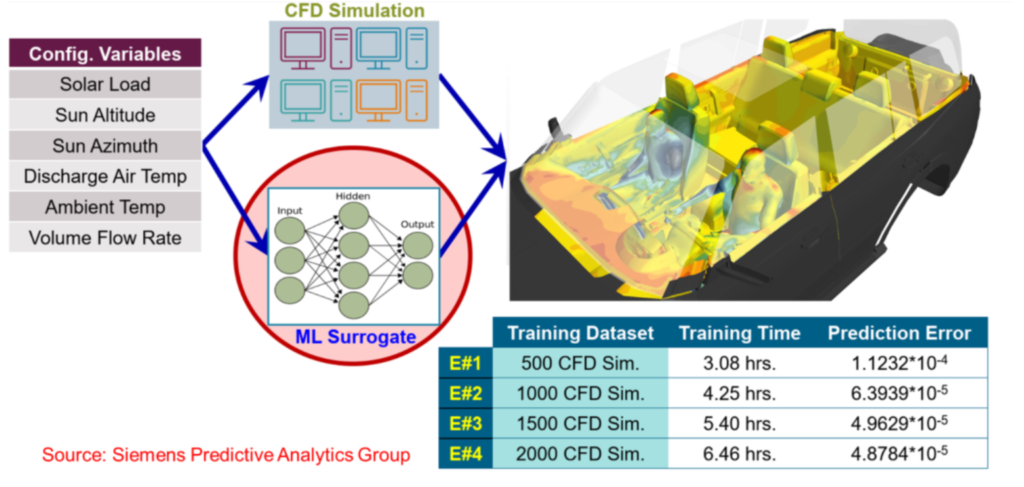
This approach needs to be applied with some caution. Still, it can provide a way of instantaneously weeding out unfeasible solutions. It allows the engineers to decide on the next steps immediately rather than having to wait for another meeting.
This approach isn’t even limited to static or steady-state simulations: Simcenter has been successfully (and accurately) applied moving engine cases, for example, across a full range of crank angles.
4. Improved Design Exploration
An extension of the previous idea (machine learning is used to predict the outcome of design changes in real-time) is that artificial intelligence can accelerate design exploration and optimization studies. Typically, these sorts of studies progress by sweeping across a range of design scenarios, rejecting any designs that fail to meet some performance criteria. Using AI and ML (Machine Learning), we can weed out bad designs to narrow down the scope of the study before running any simulations. This allows engineers to focus precious computing resources on exploring a more significant number of valid design scenarios. Modern design exploration techniques learn about your problem and adapt to it.
5. Transfer of Knowledge
The accumulation of knowledge guides every design process. Early in the design process, that knowledge is often obtained from simple low-fidelity simulations (or physical experiments) to predict critical characteristics such as pressure drop or flow rates (basically scoping calculations).
Although the complexity and fidelity of the simulations (and experiments) usually increases in subsequent stages of the design process, some design parameters will inevitably become fixed by these early simple simulations through all subsequent design evolutions. Months later – at the end of extensive experimentation and simulation – it is sometimes reasonable to ask, “what would have happened if we hadn’t fixed that parameter so early in the process?”
Artificial Intelligence allows you to map all the learning from that entire design process onto the next design when you are once again facing the early dilemma about which parameters to fix and the effect of fixing those parameters. So-called “transfer learning” allows engineers to predict what will happen later in the design process.
6. No More Wasted Data
Failure is the very fabric of innovation; it’s what success is made from. Engineering is a process of continual improvement. Engineers take existing things and try to make them better, usually by making a series of incremental changes, each intended to make a product somehow “better”: faster; stronger; lighter; more efficient; less expensive. Every successful product results from many design iterations, each of which gradually improves the product’s performance in some manner.
The problem is that for every successfully implemented design improvement, there are many more “failed iterations”. Those that either delivered no improvement in product performance or somehow made it worse. For every hard-won improvement in product performance, there is an almost infinite number of ways to break it. Predicting which changes will improve a product and which will diminish it is the art of engineering; we have to identify poorly performing design choices so that we can eliminate them. Often, the lessons learned from early failures influence the whole future design direction of the project.
Until now, the data generated from those “forgotten” simulations is often discarded (or at least archived away and forgotten). However, all of this data is incredibly useful in training Machine Learning algorithms, because as most of us know, we learn just as much from our successes as our failures.
7. Learning from Simulation AND Test
Although simulation and test are sometimes portrayed as different – or even opposing – disciplines, any sensible engineer makes decisions based on the accumulation of information gained from numerical and physical experiments. Combining that data is usually difficult, though, involving compromises in mapping from one domain to another. AI provides an opportunity to robustly combine information from multiple simulations and experiments using Machine Learning into a single model, increasing the overall predictive capability of the data.
Of course, these are just my predictions, based on recent experience of how our customers are starting to use AI and ML to improve the quality and quantity of their simulation experiences. In the recent Engineer Innovation podcast we explored how some of these developments will likely influence the engineer of the future.
If you are interested in trying AI and ML then Siemens has just announced a partnership with Monolith AI to combine our simulation tools with their artificial intelligence.
You can also check out this video about how AI and ML are being used in the automotive industry today:


