Introducing AI for NVH: how do you gather the data to train your models?

This blog was co-written with Marc Brughmans, Simcenter Engineering Services Fellow Engineer at Siemens Digital Industries Software.
There is wide interest in using AI to improve NVH in the early stage of the development process and many automotive manufacturers employ data scientists skilled in machine learning. However, these skills and tools are nothing without the necessary well-organized massive datasets to train the AI models.
There is a huge amount of data that can be gathered from testing, but this takes significant amounts of time and money. What if you could use data generated by simulation instead?
This would certainly speed up the process, but the data would only be useful if it is proved to be accurate. And while it is faster, simulation still uses a large amount of resources. Not all data is equal in its usefulness for training AI models so it’s essential to understand which data will create the most value. Focusing purely on gathering as much data as possible will result in expensive bloated datasets that cost more to produce than they are worth.
Setting goals
The first step is to identify the important KPIs of a project and the design parameters that influence them. Simcenter tools have the framework to break down a complex system like a full vehicle into separate parts where design influences overall performance and then relate the parameters of how each design influences the overall system. This allows engineers to identify which parameters and KPIs to store in the vehicle datasets that will be used for AI training.
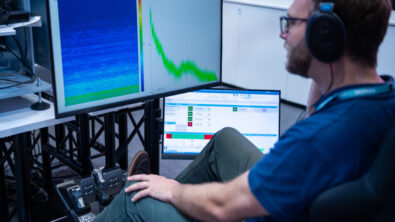
Gathering data from test and simulation
A data recording and processing tool like Simcenter Testlab gives accurate performance analysis of all the different subsystems of a vehicle and the noise experienced within. However, the number of different configurations that can be tested is limited as each time a parameter is changed the test needs to be re-run to measure performance. With finite resources available and project deadlines to meet, manufacturers need an alternative. Simulation is capable of generating this data, but its accuracy must be guaranteed for it to be used for training AI models.
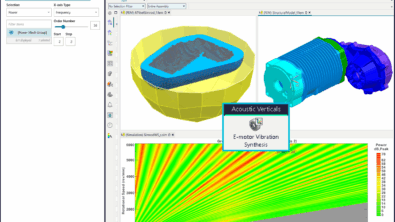
The answer is a hybrid solution that combines test and simulation to make accurate predictions at the full vehicle level and enable the generation of large datasets.
This uses a virtual prototype assembly (VPA) that consists firstly of a test-based representation of the complex vibro-acoustic system of the full vehicle. Within this, one component or subsystem is replaced by a CAE parametric representation where variables can be easily adjusted and simulations run to record the effect of changes.
Virtual Prototype Assembly framework for massive data generation
Simcenter Engineering Services created a proof of concept to demonstrate this method of creating a large-scale NVH dataset with multiple vehicles and tires. This focuses on the tire-vehicle integration as this plays a particularly important role in the NVH road noise performance attribute.
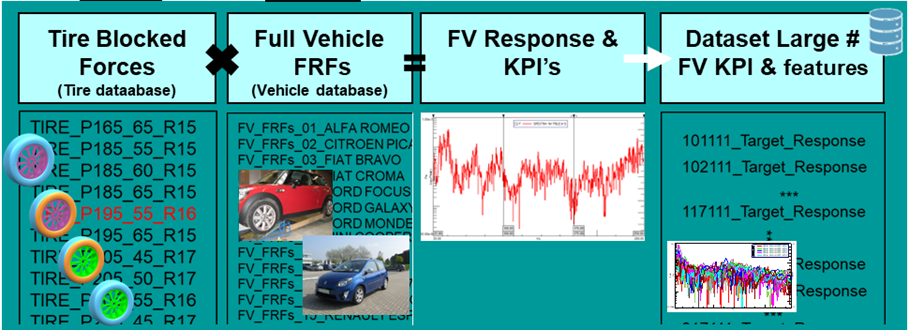
Simcenter Engineering Services experts used Simcenter Testlab to measure 20 unique cars and to build a test-based FRF system representation for each vehicle.

Next, a Simcenter CAE NVH workflow was followed to create a large data set for tires with different sizes and properties. Using NX CAD, a parametric geometric model of the tire was created and taken into Simcenter 3D to build a CAE NVH tire model. With Simcenter Nastran the tire blocked forces were simulated due to a road input excitation.
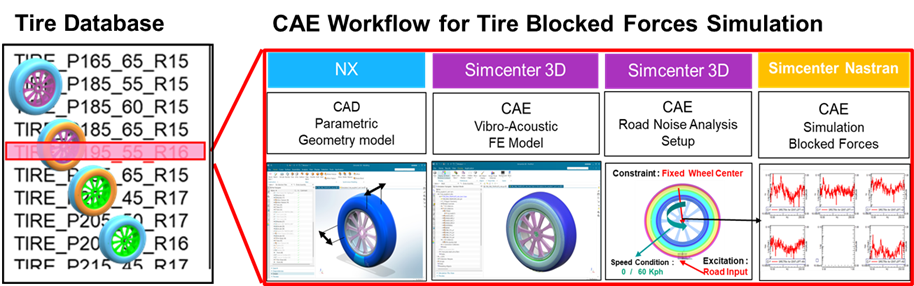
With this workflow, 17 different tires were analyzed corresponding to the respective cars. Each tire had six variants, such as stiffness and the material used for the rim. Next, blocked forces were simulated for 2 speed conditions. As a result, the tire database contained a data set with blocked forces for 102 (=17×6) tire configurations in 2 speed conditions.
Finally, the Simcenter Engineering Services experts used VPA technology to generate the massive dataset with the vehicle target performance for each combination of vehicle (# : 20) , tire (# : 102) and speed condition (# : 2).
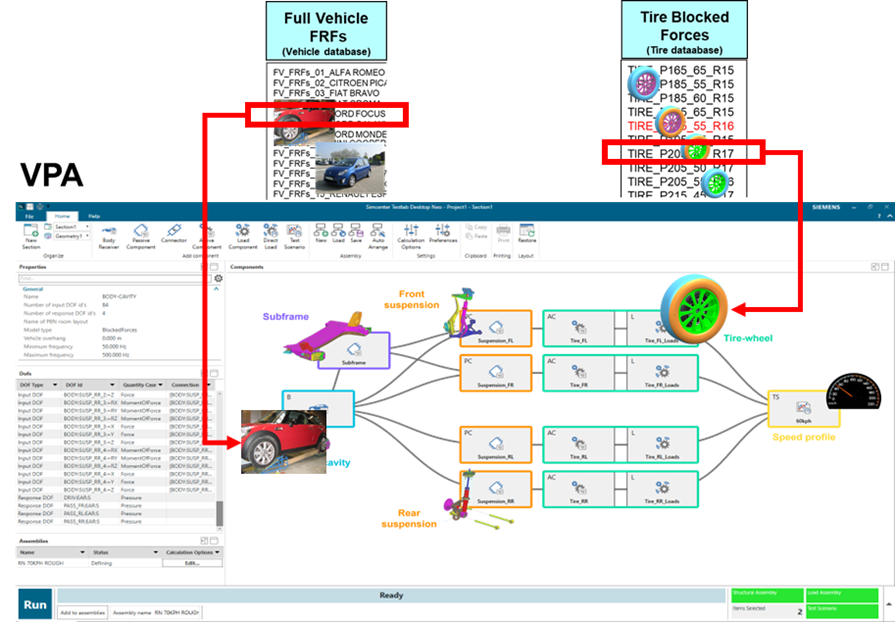
From the full vehicle response of the 4,000 configurations analyzed with VPA, NVH KPI metrics were extracted and stored together with the tire features (size, stiffness) and the car identifications.
Simcenter NVH specialists then used different visualization techniques (dashboarding) to navigate in an efficient way through the massive data and to pick up patterns and spot clusters. Presenting visual outlooks on the available data can trigger human insights that are complementary to the information extracted by machine learning.
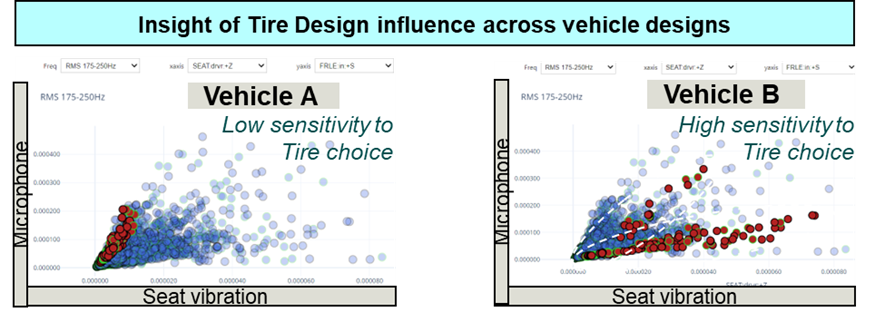
Provided this data is organized effectively, it offers many insights even before applying machine-learning such as:
- Visualizing the effect of several tires on a specific car
- Visualizing the effect of a specific tire on several cars
- Benchmarking different tires against each other
- Performance range analysis
- Target setting
The next step was to prove that machine learning could be successfully deployed to capture the mechanisms behind the complex vehicle-tire interaction. Simcenter engineers trained AI tools on this data but left one set of data out for a particular tire. It then accurately predicted the data for the missing dataset, showing that it had learned from the others and could predict performance without running further simulations.
While simulations and testing will ultimately be needed to confirm which configuration to use, AI predictions are a great help in avoiding spending time on configurations that won’t work. This gives a good indication of the material and stiffness that will be optimal, and simulation and testing can then focus on this much narrower area to create high-fidelity data that pinpoints the best setup. This saves significant time and money, de-risking investment in a large-scale testing campaign as it will have a much higher probability of success.
Lessons learned for the future: Improving data using AI
In the case where the trained dataset indicates a low level of prediction accuracy, the AI tool gives feedback on what data it needs to improve. You could generate more massive data for another 4,000 configurations, but all of this won’t necessarily be useful. Instead, the AI suggests the first 500 configurations and then analyzes it to suggest the next 500, and so on. This data-centric approach is more refined and avoids spending time and money generating data of low value, so crucial insights are realized much sooner.
Dataset management
Datasets grow over time so to maintain their value they must be effectively managed. Simcenter Testlab Workflow Automation (TWA) accounts for this dynamic character of the dataset by automating the retrieval, processing, and publishing of data as soon as it’s gathered. This ensures that when new data is added to the dataset, AI tools are retrained with it and continually improve their accuracy.
To learn more about this technology, email us at engineeringservices.sisw@siemens.com.