Timeless tales, timely simulation: La Fontaine’s wisdom meets GPU-accelerated CFD

In the timeless fables of Jean de La Fontaine, one of the most widely read French poets, we often find profound lessons masked in simple tales. The swift Hare, confident in its speed, underestimated the steady perseverance of the Tortoise. The industrious Ant prepared diligently, while the carefree Grasshopper faced winter’s harsh realities. These narratives, rich with insights into efficiency, foresight, and the judicious application of one’s strengths, resonate remarkably with the journey of computational fluid dynamics (CFD) simulation.

Indeed, La Fontaine himself famously penned in “The Lion and the Rat”:
Patience et longueur de temps
Font plus que force ni que rage
in French, so that people can enjoy the beautiful flow of these lines, which could be translated into:
Patience and length of time
Achieve more than force or rage.
While this wisdom holds true for many aspects of life, in the relentless pursuit of engineering innovation, such “length of time” is a luxury we obviously often cannot afford. Our ambition is to transcend the need for excessive patience, to accelerate discovery, and to enable engineers to achieve their goals with unprecedented speed and efficiency.
Today, we embark on a similar narrative, exploring how Simcenter STAR-CCM+ 2602 has embraced these very principles to redefine the landscape of GPU-accelerated CFD. Our latest release introduces a trio of significant enhancements, each designed to ensure that your simulations, much like La Fontaine’s most successful characters, are not only swift but also resilient, adaptable, and ultimately, triumphant.
The wisdom of the ant
Optimizing scalability for unrivaled speed
When I was a little boy, this was the first fable we had to learn by heart: “La Cigale et la Fourmi”, or in the language of Shakespeare: “The Ant and the Grasshopper”. Inspired from ancient-Greece Aesop’s fable, La Fontaine’s Ant, ever-diligent and pragmatic, understood the power of collective effort and meticulous planning. It is a creature that, through sustained labor, achieves great feats. Similarly, the modern CFD engineer, faced with increasingly complex simulations, often seeks to harness the collective might of multiple GPUs. Yet, as La Fontaine himself observed in “The Ant and the Grasshopper”:
Work, you must, if you wish to eat.

This simple truth extends to computational resources: merely possessing powerful GPUs is not enough; one must make them work together efficiently. The challenge arises when adding more computational “ants” (GPUs) does not yield a proportional increase in overall productivity. Historically, while individual GPUs offers significant acceleration, the efficiency of this acceleration can sometimes diminish as the number of GPUs grows. It is akin to having a multitude of diligent ants, but without a perfectly coordinated system, their efforts can become redundant or even hinder each other.
With Simcenter STAR-CCM+ 2602, we have improved the core algorithms to significantly enhance GPU scalability. This endeavor ensures that as you harness more GPUs, their collective power is utilized with unprecedented efficiency, much like a perfectly organized colony of ants. The changes translate directly into faster simulation turnaround times, particularly for the most demanding, large-scale models. This optimization applies universally, benefiting both NVIDIA and AMD GPU users, allowing every resource to contribute maximally. This advancement ensures that your GPU investments are not just powerful, but intelligently coordinated, transforming a multitude of powerful individual components into a seamlessly integrated, high-performance computing engine, truly making the best of your GPU resources.
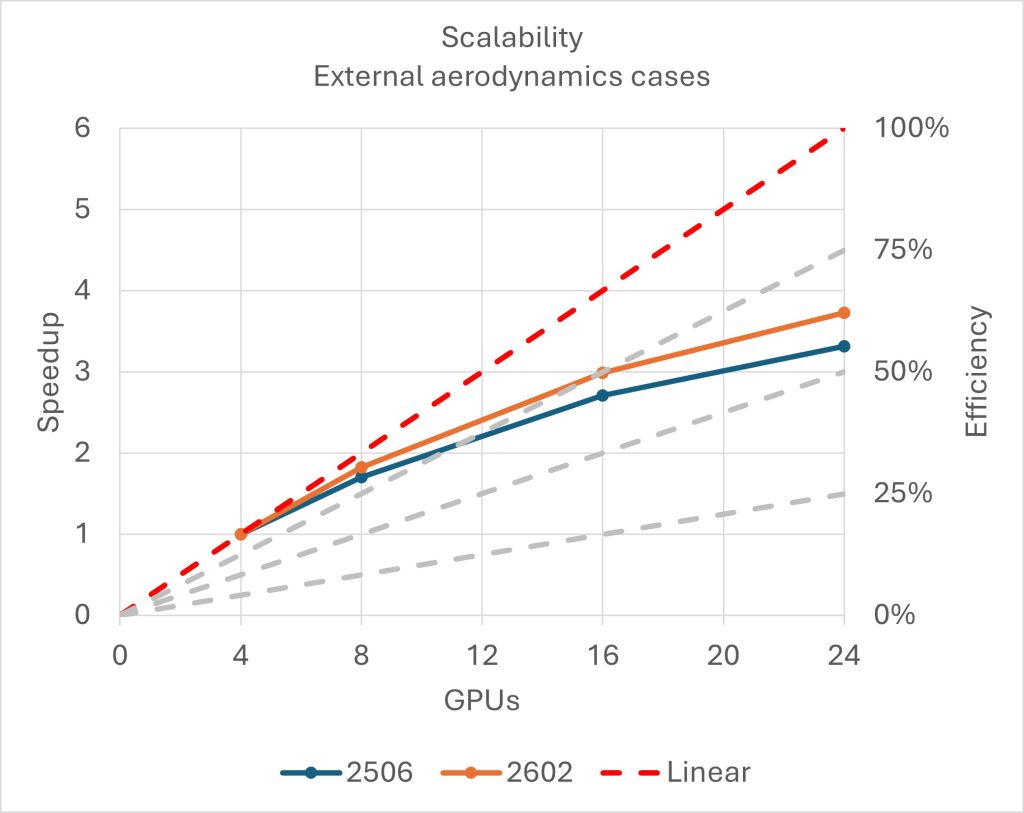
To illustrate this, the scalability graph in Figure 1 shows the improvements relative to release 2506 for internal benchmark models of external aerodynamics with various solver configurations (both steady and unsteady, segregated and coupled flow solvers) and mesh sizes (57 and 106 million cells). The reference values are measured for a single node with 4 NVIDIA A100 GPUs (speedup of 1).
Increasing the GPU count from 4 to 8, 16, and 24, the 2506-to-2602 speedup factors gradually grow, reaching an improvement of 13% with 24 GPUs: in other words, the performance efficiency grows from 55% to 62%. This actually becomes even more interesting when looking at the pure elapsed time, as seen in Table 1: the average time per iteration is reported for this same selection of cases, together with the relative improvement introduced in Simcenter STAR-CCM+ 2602. With 24 GPUs, the performance gain reaches up to 30%, meaning that productivity can be increased by almost one third.
| GPUs | 2506 | 2602 | 2602 vs 2506 |
| 4 | 1.31 | 1.27 | 3.42% |
| 8 | 0.95 | 0.69 | 27.02% |
| 16 | 0.59 | 0.42 | 28.27% |
| 24 | 0.49 | 0.34 | 30.07% |
The emergence of the mosquito
Unlocking AMD GPU power on Windows
La Fontaine’s “The Lion and the Mosquito” tells a captivating tale of an underestimated challenger. The tiny Mosquito, often dismissed, dared to confront the mighty Lion, and through its agility and persistence, ultimately prevailed, proving that even the smallest can overcome the seemingly insurmountable.

In the realm of CFD, a similar dynamic has existed. For a long time, NVIDIA GPUs, akin to the mighty Lion, have held a dominant and well-supported position for GPU-accelerated CFD. Meanwhile, powerful AMD GPUs, much like the agile Mosquito, have been making significant strides in hardware capabilities, yet their full potential for CFD simulations on Windows workstations remained largely untapped. Users possessed these powerful cards, but the software bridge to fully utilize them was not yet built.
Simcenter STAR-CCM+ 2602 addresses this directly by introducing full support for AMD GPUs on Windows operating systems, in an effort for hardware agnosticism. This pivotal development removes a significant barrier, democratizing access to high-performance GPU computing. It is the enablement that allows the AMD hardware to truly demonstrate its capabilities, challenging previous limitations and proving its worth. Engineers who have invested in AMD hardware for their Windows workstations can now fully leverage these powerful cards to accelerate their CFD simulations, mirroring the capabilities previously exclusive to Linux environments or NVIDIA users on Windows.
This expansion is more than just a feature; it is an opening of new frontiers. It empowers a broader spectrum of engineers to harness the raw computational power of their hardware, fostering innovation and accelerating design cycles without platform limitations. It is about ensuring that the agility and strength of your hardware, regardless of its lineage, can be fully realized within Simcenter STAR-CCM+, ensuring you can truly make the best of your NVIDIA and AMD GPU resources.
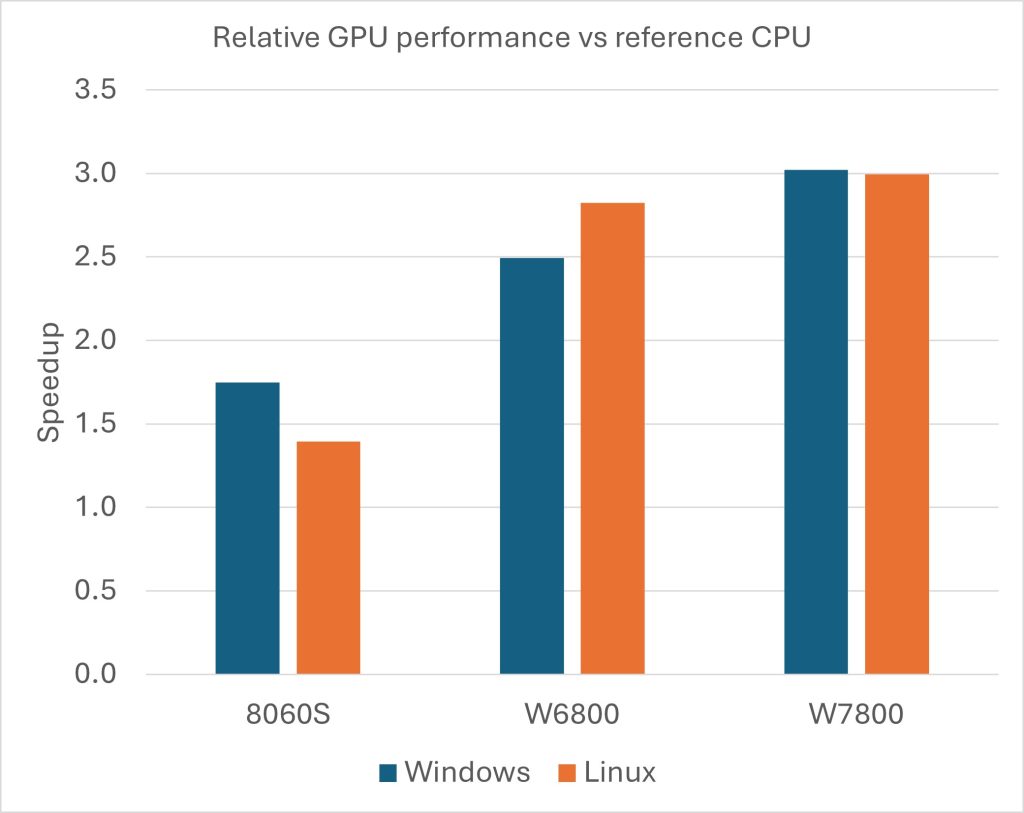
As an example, Figure 2 reports the performance of several benchmark cases calculated on three different AMD GPU types on Windows, relative to a reference 16-core CPU performance on AMD Ryzen AI Max+ PRO 395 processor: the AMD Radeon 8060S GPU, the AMD Radeon PRO W6800 GPU and the AMD Radeon PRO W7800 GPU.
The test models include a multi-region turbocharger (7 M cells), a nuclear reactor downcomer internal flow (9 M cells), an external aerodynamics car (21 M cells), as well as an SPH lubrication gearbox (16 M particles). For completeness, the performance is also compared with Linux.
First, we can see that all 3 GPU types report a better performance than the reference 16-core CPU, with an acceleration factor ranging between 1.39 and 3.02: this means an equivalence of 1 GPU for 22 to 48 CPU cores. Comparing the 3 GPU models, the more recent AMD Radeon PRO W7800 GPU is clearly showing the best performance.
Finally, running those tests both on Window and Linux, the difference in performance is larger with the AMD Radeon 8060S GPU (up to 20%), whereas it is very contained with the AMD Radeon PRO W7800 GPU (no more than 1%): looking at the detailed results, some models show better performance on Windows, and others on Linux.
The balanced approach of the oak and the reed
Harmonizing CPU and GPU resources
Consider now La Fontaine’s fable of “The Oak and the Reed” (my favorite!). The mighty Oak, rigid and unyielding, stood firm against the wind, while the humble Reed, bending with the gusts, survived the storm. This tale speaks to the power of adaptability and the wisdom of knowing when to stand firm and when to yield. La Fontaine concludes:
The Oak, with all its strength, was rooted fast; The Reed bent low, and let the tempest past.

In high-performance computing, particularly within GPU nodes, a similar dynamic exists. While GPUs excel at massively parallel computations, certain simulation tasks—such as surface wrapping, rigid body motion, or even the intricate post-processing of multiphase cases—remain inherently CPU-bound. The challenge arose when a one-to-one CPU-to-GPU ratio on a node could lead to underutilized CPU resources during GPU-intensive phases. It was akin to the Oak standing firm, while the Reed (representing the CPU’s potential for flexible contribution) remained rigid when it could have yielded and contributed.
Simcenter STAR-CCM+ 2602 introduces adaptive utilization of CPUs on GPU nodes. This intelligent mechanism allows the software to dynamically engage available CPU cores for tasks that benefit from multi-threading, even while the GPUs are heavily engaged. This means that those CPU-bound portions of your simulation no longer have to wait for the GPUs to finish their work, nor do the CPUs remain idle when they could be contributing. It embodies the wisdom of the Reed, adapting its approach to the prevailing conditions rather than rigidly adhering to a single mode of operation.
The benefit is a more holistic and efficient use of the entire computing node. Simulations that involve complex pre-processing, specific physics like sliding mesh (which sees particular advantages here), or detailed post-processing now experience significant speed-ups. It is the ultimate embodiment of teamwork, where every component, be it CPU or GPU, contributes optimally to the overall simulation effort. This harmonious approach ensures that your computing resources are not just powerful, but also intelligently coordinated, allowing you to make the best of your CPU-GPU resources and truly accelerating your path to innovation.
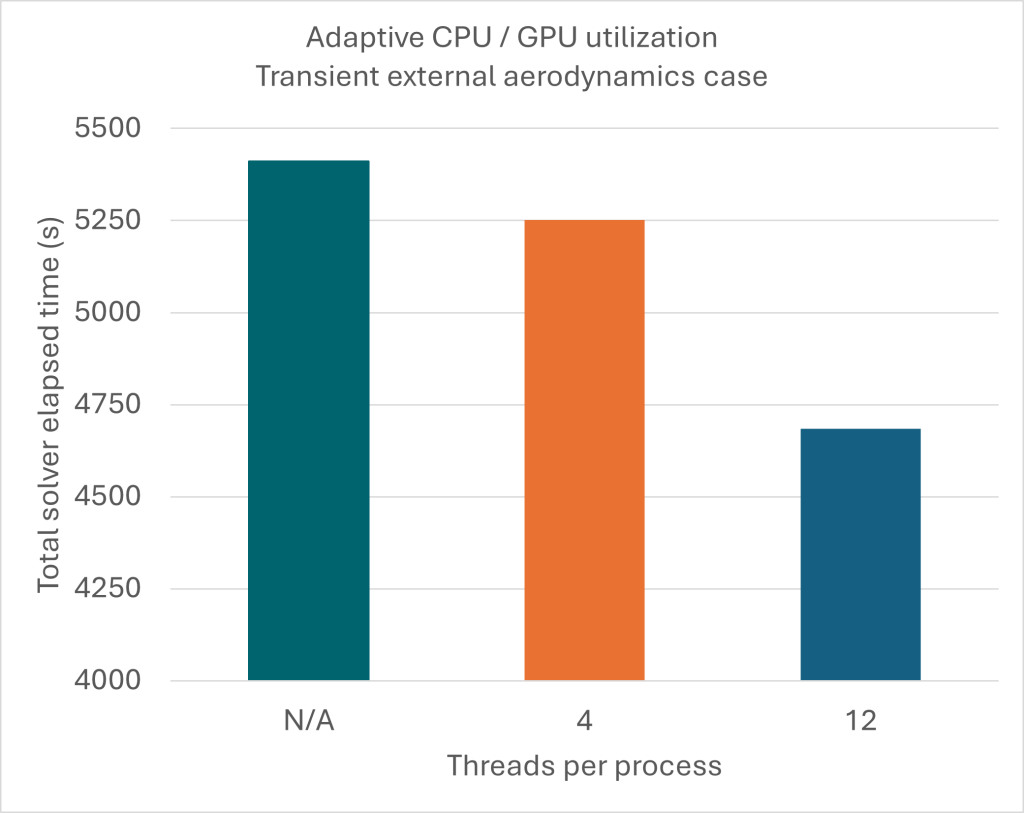
As an illustration, a 140-million-cell transient external aerodynamics car model with steady state DES (Detached Eddy Simulation) solver and 4-interface sliding mesh is considered (see representation in Figure 3). The physical time of the simulation is 0.25 s. The case is run on 2 nodes of a cluster with 4 NVIDIA A100 GPUs per node. Figure 3 reports the total solver elapsed time for 3 configurations: 8 GPUs only, 8 GPUs with 4 CPU threads per process, and finally 8 GPUs with 12 CPU threads per process. The computational cost can then be reduced by 13%, highlighting the benefits of combining the available CPU and GPU resources.
Unleash next‑level simulation efficiency with GPU-accelerated CFD
The advancements in Simcenter STAR-CCM+ 2602 are more than mere technical updates; they represent a philosophical alignment with the enduring lessons of efficiency, adaptability, and optimal resource utilization found in La Fontaine’s fables. By enabling GPU-accelerated CFD through enhanced GPU scalability, AMD GPUs support on Windows, and intelligent harmonization of CPU and GPU resources, we are not just accelerating simulations; we are empowering CFD engineers to achieve deeper insights, faster innovation, and a more streamlined workflow.
We invite you to experience this new era of CFD simulation. Update to Simcenter STAR-CCM+ 2602 and witness how the wisdom of the Ant, the triumph of the Mosquito, and the balanced approach of the Oak and the Reed can transform your most challenging engineering endeavors into triumphs of computational excellence.
Share your experience with Simcenter STAR-CCM+ to help your peers make informed decisions.


