Getting your Safety Architecture just right

Introduction
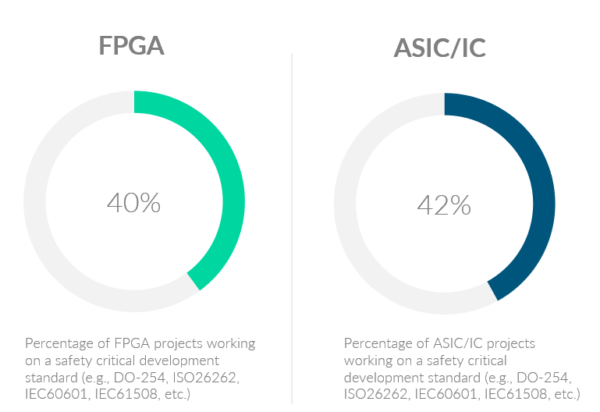
In a recent industry survey, roughly 40% of ASIC and FPGA project starts had functional safety part of their scope [2020 Wilson Research Group Functional Verification Study]. That’s across all sectors, Automotive, Aerospace, Industrial, etc., where each has a specific standard to address functional safety (ISO 26262, DO 254, MIL-STD-882E, IEC 61508, etc.). While terminology differs between standards, the main focus does not. They all care about protecting safety critical functions of a design from both the effects of systematic errors and random hardware faults.
This blog entry focuses on protection from random hardware faults. To do that, designs implement safety mechanisms, but where and how many can be a challenge.
Safety Mechanisms accomplish the protection by the combination of the following:
| Strategies to address faults & failures | Examples |
|---|---|
| Detecting a fault | A lock stepped processor can detect a fault internal to one of the processors. |
| Mitigating a fault | ECC can correct a single bit corruption fault. |
| Tolerating the fault | Three-way voting provides fault tolerance allows the operation to continue with the fault present. |
| Controlling the Failure (due to fault) | Operating in a degraded state. For example, reducing the operating speed of the automobile. |
| Avoiding the Failure | Taking a function offline. For example: disabling cruise control when a fault occurs in the LIDAR) |
Cost of Safety Mechanisms
It is a truism that functional safety adds to the cost of the development and to the unit price of a product. The question is how much. The other truism is that no matter what, the cost will always be perceived to be too high for everyone involved – customer and developer. Since safety mechanisms factor heavily into both the development and unit costs, it is important to find ways to optimize the safety mechanisms. What are those costs?
Development Costs
The following increase development effort (and therefore costs) compared to the baseline function of the design:
- Every safety mechanism has to be designed and implemented (coding, synthesis, timing analysis, etc.)
- Every safety mechanism has to be functionally verified. And since safety mechanisms require a ‘fault’ to be activated to trigger their function, the verification of safety mechanisms is not just in writing test cases to create stimulus but also requires the infrastructure in test benches to implement fault injection while predictors and scoreboards will require the extra knowledge that a fault was injected and expected behavior under a fault condition. The complexity of the verification will vary greatly with the function and the safety mechanism.
- In some cases, individual safety mechanisms may want to have their expected diagnostic coverage validated.
- ISO 26262 requires effort in tracing requirements throughout work products including design specifications, verification plans, verification specifications, test cases, and test results.
| Best Practice: It is important to separate the verification of the safety mechanism from the creation of the metrics required by ISO 26262 (SPFM, LFM) typically done through a fault campaign. A fault campaign is not where you want to verify the function of safety mechanisms. A fault campaign will assume that safety mechanisms are “known good” given the sheer magnitude of the faults being injected into the design. Fault campaigns are where you want to understand reasons why metrics are missed, not functional correctness of the design including safety mechanisms. |
Unit Price / Integration Cost
For unit price which typically tracks with packaging and the die area of design, the following increases can be expected:
- Every hardware safety mechanism will add gates to the design, resulting in increased power and area. Increased power can create needs for higher cost packaging and cooling requirements.
- Power requirements may have an indirect cost to the integrator of the product. For example: Heat Sinks, exotic cooling, larger power regulators, PCB impacts on power planes, etc.
- Safety Mechanisms that add to the IO Count of design will also influence die and package costs. In addition, failure rates in an Integrated Circuit are typically dominated by packaging. Minimizing IO/packaging requirements has a direct impact on the overall FIT / PMHF of the final product.
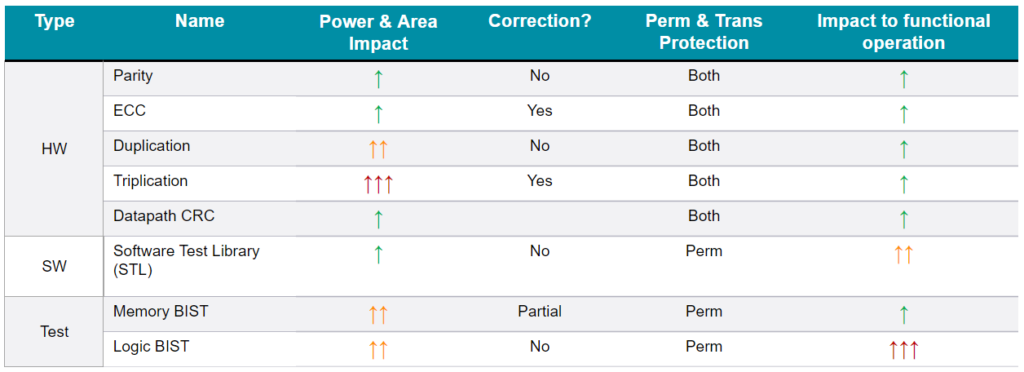
Figure 1 below highlights some key attributes of safety mechanisms commonly seen in safety critical IP’s and IC’s.
Create a Strategy
Clearly a strategy is needed for managing the needed safety mechanisms in a design.
Plan Early
An efficient safety strategy is created starting early, at the architectural phase, and developed with your safety requirements. Safety mechanism development and verification that is in concert with the rest of the design development saves time and effort. Retrofitting safety mechanisms into designs creates unnecessary iterations, increasing effort, time, and risk
Start at the highest level of the design
A safety mechanism identified at a higher level is likely to be broader in its coverage, removing or reducing the need for lower-level safety mechanisms. Lower-level mechanisms can address gaps uncovered during safety analysis. Higher-level mechanisms are also harder to retrofit requiring more changes to the architecture and design.
Understand that safety mechanisms can and do overlap
Typical designs have multiple safety mechanisms scattered throughout hardware and software that often have overlapping areas of coverage. The safety architecture should understand and leverage this overlap.
For example: An end-to-end data path that includes a CRC does not need to have low level parity checkers in the data path. Also, meeting safety metrics should be considered a team sport for the IP or SoC being designed. Meaning that it doesn’t matter if a fault is detected by one or many safety mechanisms, as long as it’s at least one. If safety mechanisms provide coverage for neighboring logic, take it. There’s no extra credit awarded.
| Best Practice: It is important not to overengineer with excessive measures. While it may be really safe, the overengineering adds cost. For example: A design that is intended to meet ASIL B metrics that is overengineered is likely to be more expensive and may not be cost competitive. |
Safety Mechanisms can include firmware, software, and even the system itself
Achieving safety is not a hardware only problem. It is quite common for large SoCs to have a significant percentage of safety mechanisms implemented in Software or Firmware.
Understanding the context of a product in a system can also provide opportunities for the system to provide a level of coverage. Protocols such as PCIE and Ethernet will carry coverage into portions of a design that implement those protocols. A watchdog timer on a PCB or connected MCU may provide additional coverage for some operations. Additionally placing requirements on the integrator for safety mechanisms can be a reasonable tradeoff.
Create confidence in your metrics as early as possible
Discovering that the design has missed its SPFM or LFM metrics targets can have a dramatic impact on the project. Increasing metrics means design changes and a retriggering of many of the development and verification steps as well as requiring many of the ISO 26262 steps to also be revisited (For example: Safety Analysis and Confirmation Reviews).
To accomplish this, it is prudent to:
- Be conservative in assigning diagnostic coverage when using Engineering Best Judgement
- Use tools like Siemens SafetyScope to explore the design as early as possible. Find the unexpected gaps in metrics well before the design is frozen and long before fault campaigns are executed.
Conclusion
It’s important to understand that decisions around safety mechanisms impact project and product costs and schedules, so planning for an efficient protection scheme for your design upfront and across the complete hardware and software design is well worth the time. To paraphrase a fairy tell, we want the design’s safety architecture to be just right. After all, too little is not a safe design, and too much is too expensive a design. We’re looking for just right.
If you are interested in learning more about how Siemens software automation tools can help your team define that optimal set of safety mechanisms, please reach out to your local sales team or go here.
Other Topics
This post is part of a broader safety series highlighting the challenges practitioners face during the development of safety critical ICs. To view other posts in the series, please refer to Guidelines to a successful ISO 26262 Lifecycle

