MLMM: increase efficiency with Modal Analysis

Last week, we had a very interesting team building activity: ‘How to be productive and improve our interpersonal skills at the same time.’
Well, one of my colleagues had an idea and decided to make an experiment using modal analysis. Yes, you read that right… I’m really talking about modal analysis! How can it be used for a group activity?
It was a surprise for the complete department. Everyone was involved, technical and less technical people, and only a little knowledge of Testlab was required. An so, we all participated in a very interesting game.
Let the game start!
The complete department was divided into groups. Each had the same database from which we could perform a modal analysis. People on the same team could interact with each other, make suggestions or give their opinions. However, everyone was responsible for their own results. And because I like challenges, I was really curious about the outcome. I have experience with modal analysis, so I was not worried, but some of my new colleagues were.
The dataset was quite big. I thought to myself: How many inputs were used? And what structure are we considering? It’s all so damped!
First Results
At the first attempt, it was clear who was an expert and who was not: a variety of curves and colors everywhere in the results! Some of the synthesized FRFs didn’t seem even close to the original ones.
The second step was to give some boundary conditions and insights to all the participants. I was impressed by how the results were getting better, but still not perfect. There were some spreads of the results based on the user experience and a high number of iterations was needed to have the ‘perfect’ results.
From the social point of view, people started to iterate much more, talking with the next colleagues to check the improved results.
The last step was to let us use extra help, considering also the knowledge gained earlier that day. All the users performed the modal analysis using a new solver: Maximum Likelihood estimation of the Modal Model (MLMM).
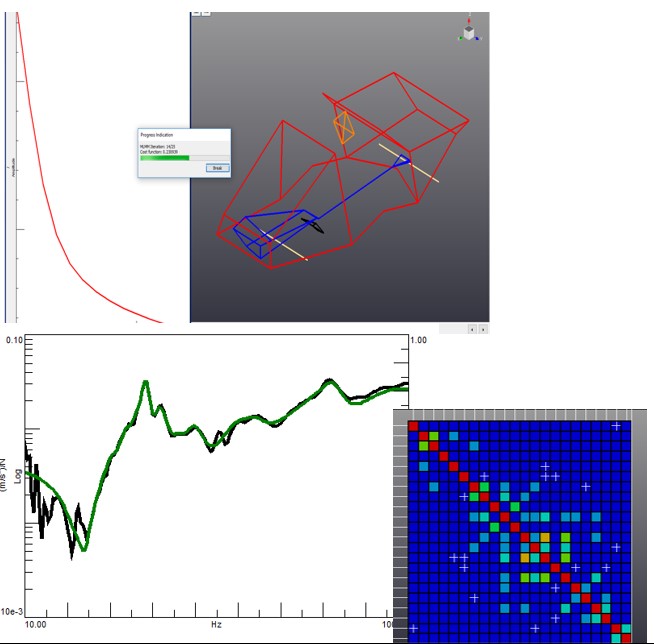
Wow, everyone was impressed at the new results!
MLMM to the rescue
The acronym may be difficult to pronounce, but the technology is actually easy to use.
The shapes of the synthesized FRFs were so close to the original ones, especially for very damped modes. And the variation of the data between different users was small. Of course, it’s not a magic box—we needed a good model to start with, and the engineering judgement of the user is needed. MLMM gave back a new optimized modal model, doing the iterations automatically.
MLMM removed the subjective aspect that comes from manual interaction needed to get good results.
An extra advantage was that the mode shapes could be used directly for CAE correlation (the output is immediately a reciprocal modal model).
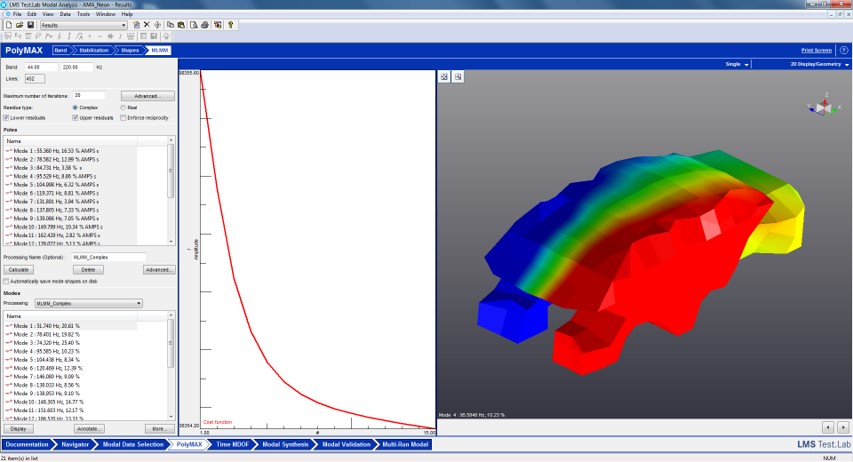
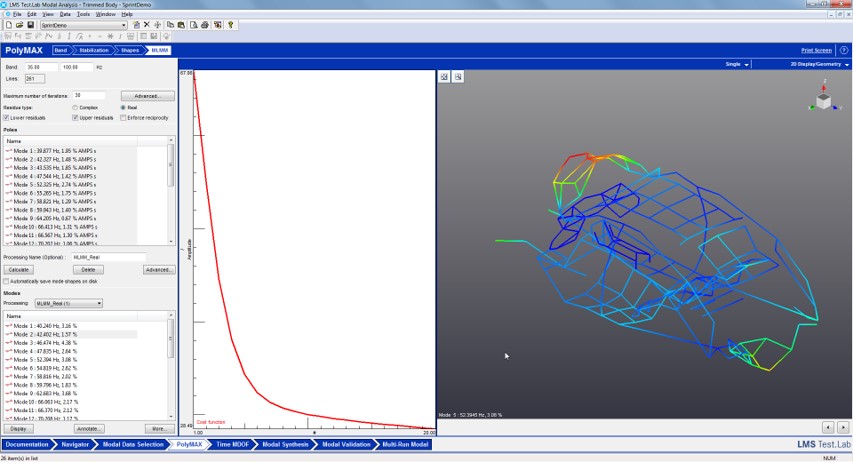
No more boring jobs
In conclusion, MLMM is ideal for very damped structures as trimmed bodies or for acoustic modal analysis or when many inputs are needed. Different users will have the same results a lot faster, even for complex stabilization diagrams.
It can also be used with more simple scenarios, because it will help the engineer in getting optimal results faster and will do the boring job for the user. The engineer can then focus on the fun part of the analysis and in the interpretation of the results, by verifying the design assumptions and by identifying countermeasures to avoid malfunctioning.
If an easier way exists, why wouldn’t you take it to achieve your goals faster?
If you want to learn more about MLMM, just follow this link or read this Solution Brief.


