Rapid CFD surface wrapping: unlock speed and consistency in meshing

I love spending my free time reading a nice book, especially with a good cup of coffee in hand. I especially enjoy wandering through bookstores, browsing the shelves, and discovering unexpected reads. During one of these visits, I came across a book that immediately caught my attention: Prediction Machines by Ajay Agrawal, Joshua Gans, and Avi Goldfarb.
Let’s be honest: can you name a person who is not at least a little curious about AI/ML these days? In their book, the authors explain the “simple economics of AI and describe how the technology is used for point solutions”. In one of the chapters of the book, the following stood out to me:
With better prediction comes more opportunities to consider the rewards of various actions, in other words, more opportunities for judgment. And that means that better, faster, and cheaper prediction will give us more decisions to make.
While this book focuses on AI and machine learning, this quote resonated with me, as the same idea applies in the world of engineering simulation, particularly in CFD. The ability to make faster, better-informed design decisions is crucial for engineers, regardless of simulation intent. The pressure to innovate and stay competitive only intensifies the need to boost productivity and accelerate simulation workflows.
Furthermore, the need to create high-fidelity digital twins with increasing complexity has intensified, as engineers want to include as much physical realism and geometric detail as possible. Therefore, fast meshing is a strategic enabler that can bring a competitive advantage, empowering engineers to accelerate product development and get their products to market faster. To support this, we strive for solutions that accelerate CFD workflows, enabling you to quickly evaluate numerous design variants. For meshing, this can involve everything from optimizing individual workflows to Message Passing Interface (MPI) distributed memory parallelization, i.e., the ability to simultaneously execute meshing tasks on multiple CPUs.
In this blog, we will explore how recent enhancements in Simcenter STAR-CCM+ have increased meshing performance, enabling engineers to increase their simulation throughput and get faster insights.
Accelerate geometry cleanup with MPI surface wrapping
One of the key differentiators of Simcenter STAR-CCM+ is the pipelined workflow from CAD to solution that enables engineers to handle complex geometry. Many simulation workflows involve huge CAD assemblies with tens of thousands of parts. These CAD files often include very large assemblies and “dirty” geometry. By “dirty” we mean input geometry that may have holes, intersections, may need defeaturing, contain overlaps, and/or non-manifold vertices or edges. Manually cleaning and healing such geometry can be a labor-intensive process, potentially taking days or even weeks to complete.
One of the key tools for preparing the geometry for meshing in Simcenter STAR-CCM+ is the Surface Wrapper. The Surface Wrapper can take any arbitrarily complex CAD or tessellated part and generate a watertight, manifold surface. It works by effectively “shrink-wrapping” a high-quality triangulated surface mesh onto the discretized geometry. One of its key strengths is the ability to accurately preserve geometric features such as sharp edges and corners. In version 2310 of Simcenter STAR-CCM+, we introduced the first MPI-parallelized version of the Surface Wrapper, offering significant performance improvements over the shared-memory parallel version, also known as the “Legacy Wrapper”. In that first version, we demonstrated up to 43% reduction in wrapping time compared to the Legacy Wrapper.
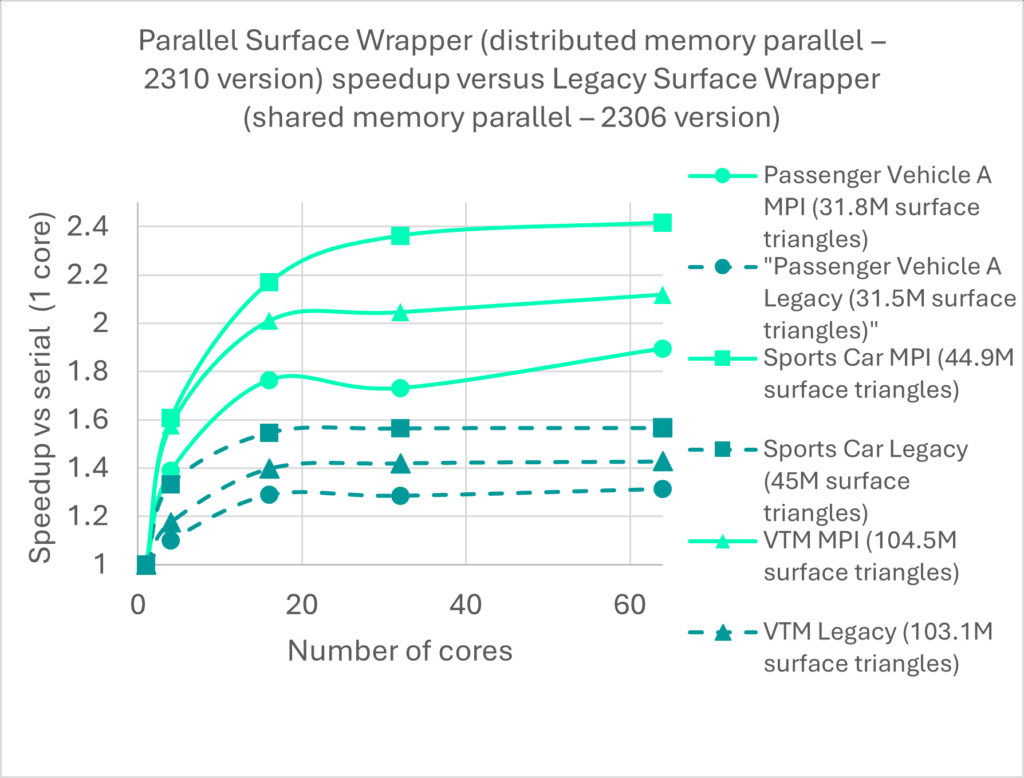
However, this performance increase is not enough for very large cases, and in line with our commitment to continuous improvement, in the Simcenter STAR-CCM+ 2510 version, we are releasing phase two of the MPI Surface Wrapper. Let’s take a look at the performance improvements.

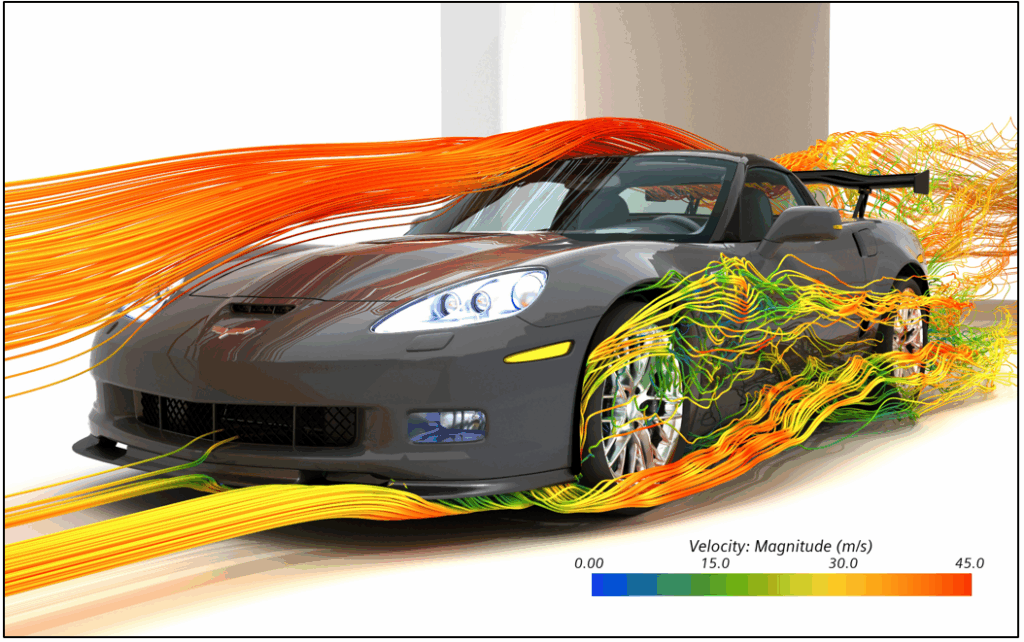
As illustrated in Figure 2, the MPI Surface Wrapper in version 2510 delivers up to ~2x faster performance compared to version 2506 (Phase 1 of MPI Surface Wrapper). When compared to the Legacy Wrapper, the speedup reaches up to 5.6x. For a complex geometry, such as the Corvette car, where the total volume mesh count is 93M cells, it takes only 6.5 minutes to wrap the entire geometry on 32 cores (Intel® Xeon® Gold 6442Y).

What about wrapping a larger case? In the Corvette case, the Surface Wrapper generates 37.4M surface triangles. In comparison, the Maserati Ghibli case, as shown below, is significantly larger, requiring only 9 minutes to wrap with 56.3M triangles and resulting in a final volume mesh of 142M cells.
Ensure mesh consistency
Speed is a key attribute, as previously described, but consistency of results is equally important for ensuring trust in the simulation results. We aim to maintain consistency across both software versions and different core counts.

In extensive testing, the variation in the final surface triangles was less than 1%. Specifically, for the Corvette geometry as shown below, the variation in final surface triangle count between 2506 and 2510 was just 0.005%. In version 2510, across three runs using 1, 32, and 48 processors, the variation compared to the serial execution was only 0.06%.
Such consistency in the surface wrapper results means that the subsequent remeshed surface and resulting volume mesh will also remain consistent.

Surface remesher performance enhancements for faster meshing
The MPI Surface Wrapper delivers significant performance gains and accelerates workflows where it’s applied. However, surface meshing can still be time-consuming, depending on the geometry. In version 2506, we have made enhancements to the surface remesher that could result in a reduction of up to 40% in execution time. However, this depends on the case complexity and the quality of the input CAD.
For example, the Corvette geometry (93M cells in the volume mesh) involves less clean geometric input compared to the DrivAer geometry case (855M cells in the volume mesh), which did not require running the Surface Wrapper. This means that if I were to select such surface mesh settings to build a volume mesh for the Corvette that approaches 855M cells, the process would be substantially longer. This highlights the importance of context when assessing the performance of meshing algorithms.

Optimize meshing performance with improved algorithms and hardware
A critical part of the product strategy for Simcenter STAR-CCM+ is to increase the performance of every algorithm, including meshing. Our product development team is committed towards this goal. Meshing performance, though, is not only related to the algorithms used or the size of the model. For example, excessive mesh refinement where it is not needed could negatively impact the turnaround time of any CFD simulation.
Nonetheless, let me tell you about another factor that can dramatically impact simulation throughput: the hardware used.
I will compare two different AMD processors by evaluating the time required to generate a surface mesh using a single core (since the surface remesher in Simcenter STAR-CCM+ operates currently in serial mode). The processors involved are the AMD EPYC 7532 Rome and the AMD EPYC 9755 Turin (fortunately, some colleagues generously provided me with access to a new machine, just in time for this test!). I will create a surface mesh for both the DrivAer and Maserati Ghibli geometries.
For which processor would you bet your money on?
AMD EPYC 9755 Turin outperforms its older cousin (younger by 4 years and a couple of months) and delivers faster surface meshing by up to 1.9x, as shown in the figure below. However, as we previously discussed, context is key when evaluating meshing performance, and here is why the surface mesh for a much simpler input geometry takes considerably less time (regardless of the end volume mesh count) than the Ghibli case (surface wrapper was needed to run before the surface remesher). Both cases were surface meshed using the same version of the software (Simcenter STAR-CCM+ 2510) but on two different machines.
Even without parallelism, the newer processor delivers noticeably faster mesh generation. This is primarily because surface meshing is memory bandwidth-bound. This means that its performance depends less on clock speed and more on how quickly data can be transferred from memory. The AMD EPYC 9755 Turin features a larger and more efficient L1/L2/L3 cache structure, supporting DDR5 memory with higher bandwidth and lower latency compared to the DDR4 used by the AMD EPYC 7532 Rome. It is also worth noting that other meshers will benefit from newer hardware as well, though the extent of the performance gains will vary depending on the meshers involved and the case complexity.

Drive innovation with rapid CFD surface wrapping and faster surface meshing
Meshing performance is crucial for CFD simulations, enabling innovation across all industries. The evolution of CFD surface wrapping in Simcenter STAR-CCM+ 2510 marks a significant leap forward for simulation engineers. By further harnessing the power of MPI parallelization, the latest Surface Wrapper delivers fast, reliable, and scalable meshing, even for the most complex and “dirty” geometries. These advancements mean engineers spend less time cleaning up CAD and waiting for meshes, allowing them to focus more on exploring design space and making more design decisions faster and with greater confidence.
And while we are forging ahead to enable you to make better predictions faster, I read Ajay Agrawal state:
Having better prediction raises the value of judgment. After all, it doesn’t help to know the likelihood of rain if you don’t know how much you like staying dry or how much you hate carrying an umbrella.
This is a call to all engineers: in AI/ML and physics-based simulation alike, the fact that predictions are faster and easier to generate makes it our core responsibility to spend more time making the right judgments based on those predictions.
Stay tuned to explore more exciting new features in Simcenter STAR-CCM+ 2510!