Concurrent BISR: Revolutionizing Memory Repair in Modern Electronics
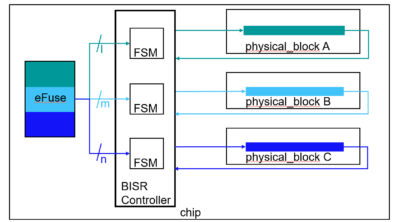
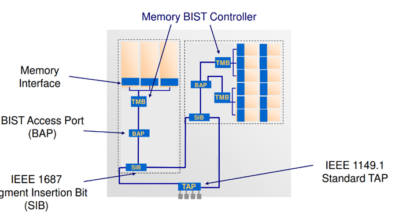
Concurrent BISR (Built-In Self-Repair) chains refer to a methodology that enables the simultaneous processing of multiple BISR chains during power-up, thereby facilitating faster loading of repair data. This approach allows for parallel processing of BISR chains, which can include a mix of compressed and uncompressed chains. The primary advantage of concurrent BISR chains is that they accelerate the loading of repair data during power-up, which can be particularly beneficial in systems where time-to-operation is critical. It’s worth noting that this feature is specifically utilized during the functional mode of circuit operation and is not applicable in manufacturing modes.
To implement concurrent BISR chains, the on-chip repair storage interface must incorporate a read buffer that supports concurrent chain loading. Furthermore, the scheme necessitates at least two BISR chains, which could be derived from distinct power domain groups or a single power domain group divided into multiple chains. The use of concurrent BISR chains can lead to an increase in fuse box size due to alterations in fuse box organization. Additionally, certain conventional repair-related scripts are incompatible with this scheme. To leverage this functionality, repair property for repairable memories must be set to the approach employing the instantiation of a fuse box to store the repair data on-chip. It’s essential to carefully evaluate the system requirements and constraints before implementing concurrent BISR chains, as it may have implications on the overall design and operation of the system.
By understanding the principles and limitations of concurrent BISR chains, designers and engineers can effectively harness this technique to optimize system performance and efficiency.
The crucial information on Concurrent BISR can be found in the Tessent manual for Memory BIST here: Tessent MemoryBIST User’s Manual
Some additional information could be found here: How do we determine the fuse_allocation value for a mixed compression scenario in the tile-based design?