Webinar Preview: Practical Flows for Continuous Integration
But First, The Backstory…
I’ll take you back to May 4th 2020 to the last in a series of verification methodology blogs – The Ideal Verification Timeline – where I pitched a complete view of our formal and simulation tool suite. That series generated some good discussion within the team here. The highlights centered around this snapshot of tool value plotted over time…

The intention there is understanding when to apply a tool during a project cycle and the relative value to expect. Basically, use tools when it’s appropriate.
Those methodology blogs were fun to put together. I learned a lot. But following the last blog, I was done with the idea of integrated tool flows (from a theoretically view at least). I moved on and started digging more into formal property checking.
<Time passes>
A few weeks ago, I was in a meeting about continuous integration. Not exactly the topic of those old blog posts, but relevant and related. I shared the value over time diagram during that meeting again. Discussion ensued. As we went, it became obvious I had overlooked a major point. I wanted to understand the value each tool brought over a project timeline. But understanding the value of each tool in an flow only goes half way. Actually capturing that value requires a tool flow within the context of a real application. Continuous integration is one application; that’s where we go next.
The Preview
Practical Flows for Continuous Integration is a half hour webinar designed to help design and verification engineers build integrated tool flows within a continuous integration system. The value of those tools flows comes through the prevention of bugs that proliferate through entire development teams. The focus is verifying code changes before they’re committed and released to teammates. Verification happens through a combination of formal tools and simulation. Each tool has a specific place and purpose to maximize both quality of code and productivity of engineering.
I like the webinar because it’s an upgrade to the two methods I’ve seen design and verification teams use for continuous integration.
Commit-And-Hope
First method I’ve seen is the ad-hoc commit-and-hope scenario. In commit-and-hope, there is no continuous integration per se. I come to a code checkpoint, then I commit and release. Maybe I do some sanity testing of my changes before committing depending on how extensive they are. But there’s no formal quality checkpoint here; I just commit my changes and hope they don’t break anyone.
Of course hope isn’t a great quality strategy so I often commit bugs that break either RTL or testbench. Those bugs get to the rest of the team which means I’ve likely broken the team as well. Productivity grinds to a halt for a few minutes up to a few hours. During that time, people are either sitting idle or scrambling to figure out what’s going on. Finally, the bug is found and fixed so everyone can carry on… until the next commit-and-hope.
Simulation-Only
The next method I’ve seen, let’s call it simulation-only, is a significant improvement over commit-and-hope because it includes a standard quality checkpoint that all code has to cross before it’s released. Usually, the checkpoint is a subset of tests from a full regression suite.
In my previous life, I’ve seen several sim-only qualification flows that worked quite well; most bugs are caught and fixed with minimal harm done. The tricky part of relying entirely on simulation though is staying efficient. Constrained random tests – even directed tests – are great for capturing symptoms of bugs. They are less good at isolating root cause. For example, I might see an SoC test fail with a packet traffic mismatch after 15min of simulation. Obviously there’s a bug there, but what is it? And where is it? And who’s bug is it? All good questions that simulation may not be great at answering.
The Upgrade: Practical Flows for Continuous Integration
Which takes us to method #3 and Practical Flows for Continuous Integration that use a combination of formal and simulation. Something that looks likes this…
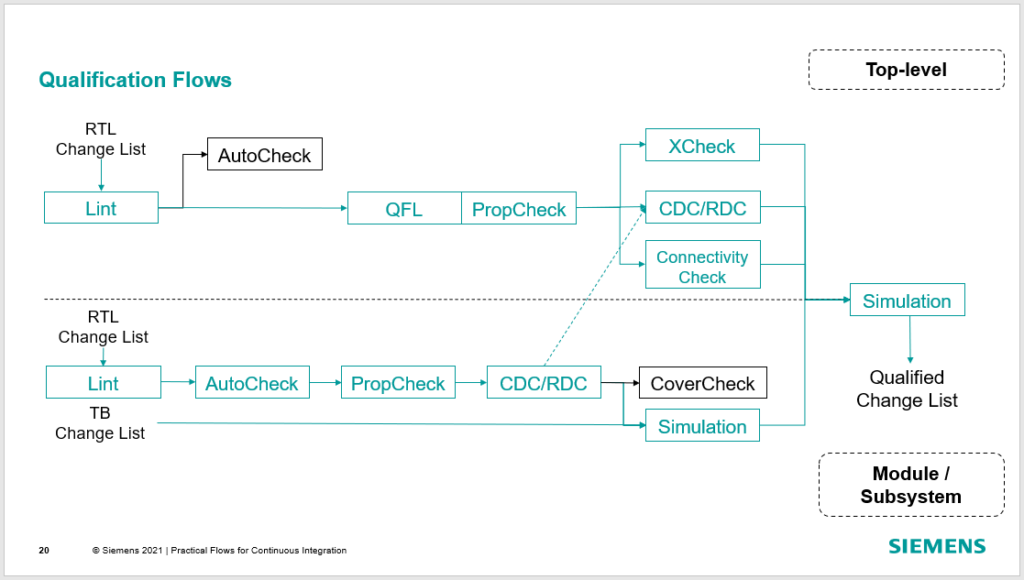
The goal with formal and simulation isn’t only high quality, it’s high efficiency. To illustrate, let’s go back the packet traffic mismatch we saw in our sim-only qualification. Somebody needs to debug that sim to find out what’s wrong. Let’s say a half hour search culminates in a simple vector width mismatch; a 7-bit value assigned to a 6-bit vector. Hardly the demon you expect but often that’s what we find; a catastrophic functional failure that materializes from a simple mistake. Doh!
Now if only there were a way to trap those bugs closer to the source instead of wading through logfiles and waveforms. Well, there is and it’s a pretty easy to use: lint. Lint finds that mismatch quickly and there is no debug. Maybe next time it’s an FSM lockup? AutoCheck finds that easily with minimal debug. Or what about a protocol violation on an internal interface? There’s PropCheck and the Questa Formal Library (QFL) for that. XCheck for X’s; CDC for clock crossings; ConnectivityCheck for verifying interconnect; etc.
Join Us on Nov 16th
The point? Effectively qualifying code in a continuous integration system requires both formal and simulation technology; formal for the root-cause isolation, simulation for the functionality.
At least that’s what I’ll propose in the Nov 16th webinar! The only way to know if I’m right is to tune in so here’s the registration link again. Hope to see you there!
-neil

