The Beginning Of The End For Coverage
Before we get started here, I’ll assure you it’s not as it sounds. I’m not talking about the end of coverage as though it’s something we’ll stop using. The end in this case is the home stretch of any non-trivial ASIC or FPGA development effort – which is almost all of them nowadays – where coverage collection, analysis and reporting consumes a team on its way to RTL signoff.
The beginning of that end is something we consistently ignore. In my 18 years as a verification engineer, having worked with many different development teams and organizations, I’ll admit to ignoring the beginning of coverage myself. I think we’ve become so accustomed to coverage closure being a mad scramble that we’ve long given up on the idea it can be anything else. Though if we step back to see that coverage does indeed have a beginning, we’ll see it also has a flow. And it’s the flow that’ll ultimately save us from the mad scramble long perpetuated in semiconductor development, growing in strength since the late 1990’s when functional coverage first became a thing.
The Beginning
In The Beginning… there was no code, no tests nor environment; there were only verification engineers and they were saying it’s going to be a while before they can show any progress because it takes a hell of a long time to build a constrained random environment. And besides, the RTL isn’t ready yet anyway. This is where the mad scramble starts; it’s the fact development takes time paired with the idea that progress during the active development phase of a project isn’t tangible enough to measure with coverage.
The first step toward avoiding the scramble is to change that early development mindset. Progress can’t be a gut feel from a black hole captured as a few lines in a status report. It needs to be tangible; a statistic, with history, that trends over time to guide decision making and objectively sheds light on the reality of our current state not to mention the delivery dates we all agree to. Which brings us to our purpose in The Beginning: capturing coverage trends that assist with objective decision making later on.
With literally everything left to do, statistics and trends can’t be yet another burden on the team. Luckily, code coverage fits the bill because we essentially get it for free. So The Beginning of coverage is easy; it’s configuring a regular regression with the code coverage enabled on day 1 with a dashboard for publishing trends. And don’t worry if it starts with just a single test or even part of a single test. That single test will grow into a full-featured regression before you know it.
The Middle
The Middle is a transition point where the focus shifts from active testbench development toward actively closing coverage, specifically functional coverage. It can be difficult to know exactly when this transition should happen. I’d say this decision is currently based on whether or not we’ve completed the planned version of a testbench. But in 100% of the projects I’ve been involved with, it’s the unplanned features that lead to schedule overruns so I’ve neve seen decisions relative to initial planning as reliable. We need a better way.
The code coverage trends developed since The Beginning provide that better way. Without a lot of in depth analysis, we can use code coverage trends to estimate the completeness of our testsbench and test suite. For example, if at the end of our planned development we’ve only exercised a third of the design, obviously we’re short on test functionality across the board. Similarly, if our code coverage is trending toward 95% but there’s 1 module down at 2%, there’s probably a specific feature that we’ve overlooked that’ll take time to address. Or maybe our coverage has stalled for several weeks even though we’re actively adding new features, a potential sign we’ve misrepresented certain configurations or stimulus patterns. These are all critical observations possible with a code coverage report and minimal analysis.
The purpose of The Middle, therefore, is to use code coverage trends to gage whether or not the active development phase of the project is winding down and we’re ready to shift focus to functional coverage closure (NOTE: I’m specifically avoiding mention around when we implement our functional coverage model. We’re here now to talk about when we start using it.)
The End
Finally back to what we’ve always known, except this time around a little method will take the madness out of the mad scramble.
Our purpose in The End is still to work toward 100% code and functional coverage closure (the exact definition of 100% of course varies by team). But using code coverage to validate a design is already well exercised gives us a couple advantages over past behaviour:
- We’re less likely to be surprised by large functional holes in our testbench; and
- We’re more likely to have found/fixed existing bugs in the design and testbench.
In short, an informal use of code coverage from The Beginning removes major coverage impediments and sets us up for a more predictable path to code and functional coverage closure in The End.
Putting it All Together
With coverage closure being such a stressful time, it’s hard to view it as being more than just a destination. But if we treat coverage closure as a progression instead of just a destination, the path we follow becomes as meaningful as the destination itself.
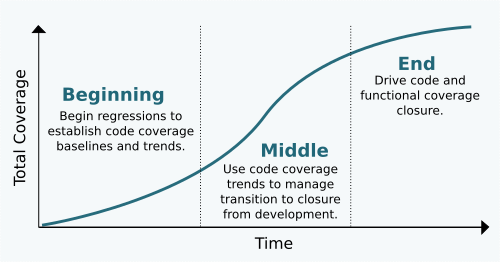
Developing early trends with code coverage will help verification engineers validate progress through testbench and test suite development. Those same trends help managers sanitize delivery estimates not to mention offer a preview of schedule overruns with earlier opportunities to react with staffing or scheduling decisions. Then transitioning toward functional coverage analysis and closure after we’ve seen all the surprises adds an element of predictability we wouldn’t otherwise have.
It’s all made possible with results from early and continuous coverage regressions. Results and, of course, a purpose for acting on them.


Comments