big.LITTLE
From time to time, a concept or some terminology pops up and suddenly everyone is talking about it. That is usually the point when I think “I wonder what that is all about.” and start to investigate. That is what happened with ARM’s big.LITTLE concept.
As a C programmer at heart, any terminology that uses the case of letters in an odd way gets my attention – and big.LITTLE is certainly an original construct. Fortunately, there is rather more to it than that …
There are a number of current technology trends that are current in the world of embedded software and a key one, that I have written about before, is reducing/optimizing power consumption. The motivations for doing this are obvious; the way that it might be achieved is less so.
Historically, power consumption was considered to be exclusively a hardware issue. Increasingly, software has become a more significant factor in the power management of a device. In general, power consumption is minimized by switching off peripherals that are not in use and reducing the voltage/frequency of the CPU when high levels of processing power are not required. Along with the availability of low power modes [suspend, hibernate etc.], these capabilities are provided by the underlying hardware [obviously], but managed by software.
ARM have always been known as leaders in low power CPUs and the popular power management techniques are widely applied on ARM-based devices. It is, therefore, unsurprising that they would come up with other, novel techniques to optimize power. This is exactly what big.LITTLE is all about.
Nearly two years ago, ARM announced the Cortex-A7, which was architecturally compatible with the more powerful Cortex-A15. At the same time, they announced the big.LITTLE concept. The idea is actually quite simple: in a multicore design, instead of simply instantiating a number of CPUs, the CPUs are configured as pairs – a high power [“big”] CPU and a compatible low power [“LITTLE”] CPU. Code is then executed on whichever CPU makes sense at a given time and the other CPU is normally powered down.
The hardware concept is, as you see, quite simple. It is the software [the operating system] that does the smart stuff. ARM envisages three ways in which big.LITTLE may be implemented:
Cluster Migration – This is the “simple” case. When the OS determines that more/less CPU power is suitable for the application as a whole, processing is swapped between the big and LITTLE CPU clusters. The OS is only “aware” of the possibility of the two clusters. The OS would either be an SMP system or a hypervisor controlling OSes in an AMP system.
CPU Migration – A more sophisticated way to control power using big.LITTLE means that the OS sees each CPU pair and swaps between big and LITTLE on a per CPU basis, as the need for CPU power demands. I guess this could be applied to an AMP or SMP multicore system.
Global Task Scheduling – The greatest flexibility is offered by this mode, where the [SMP] OS can “see” all the CPUs, both big and LITTLE, and can utilize as few or as many as are needed at many particular moment.
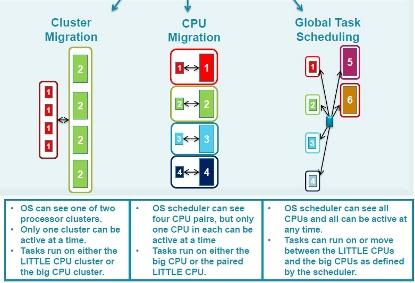
Three main software usage models for big-little. (Source: ARM)
There is certainly a logic in the big.LITTLE concept, as it addresses what [IMHO] multicore is often about: having enough CPU power for the job in hand, but being able to tune it to avoid waste. Only time will tell if ARM are on to another winner.