Navigating Reset Domain Crossings to Safety in Complex SoCs
As the complexity of system-on-chip (SoC) designs escalates, driven by the demand for more integrated functionalities and higher performance, electronic components such as processors, power management blocks, and DSP cores are proliferating. This surge necessitates a shift towards intricate power and performance management strategies, often incorporating several asynchronous and soft resets. These resets play a crucial role in safeguarding both software and hardware functional safety by ensuring systems can quickly revert to their initial state and address any pending errors or events.
The Emergence of Reset Domain Crossing Challenges
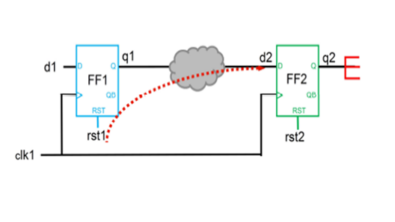
One of the critical areas where this complexity becomes a challenge is in the management of multiple asynchronous reset sources within a design. This setup leads to the creation of multiple reset domain crossing (RDC) paths. RDC paths, if not properly managed, can result in systematic faults that manifest as data corruption, glitches, metastability, or even complete functional failures. These issues are beyond the scope of traditional static verification methods, such as clock domain crossing analysis, highlighting the need for a dedicated RDC verification methodology during the RTL verification stage.
Understanding Reset Domain Crossings
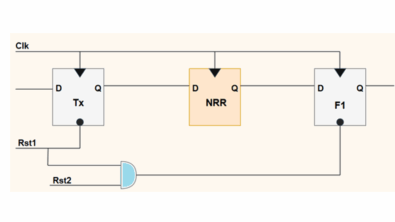
RDCs occur when a signal path’s transmitting flop is governed by one asynchronous reset, while the receiving flop is either governed by a different asynchronous reset or has no reset. It’s a misconception that a path with different reset domains at its ends is inherently unsafe, nor is it true that a path with the same reset domains is automatically safe. The reality is that the presence of soft resets can introduce metastability in designs, leading to unpredictable reset operations or, in extreme cases, device overheating during reset assertions.
The Role of Soft Resets in SoC Designs
Soft resets involve manipulating specific registers or signals to initiate the reset process. A soft reset is typically an internally generated reset that allows design engineers to reset specific portions of a system (like a particular module or subsystem) without needing to power down the entire system. This mechanism is invaluable for conserving power by selectively resetting components, thereby maintaining some operational areas while others reboot.
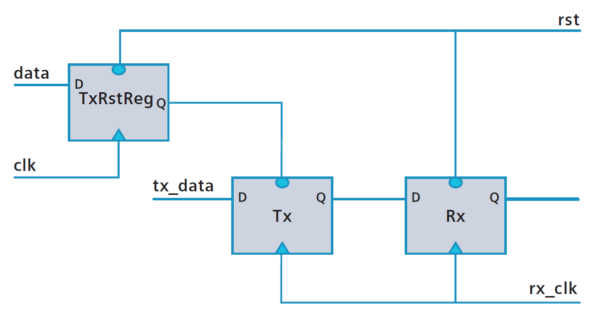
If the transmitting and receiving components are within the same asynchronous reset domain, but the transmitter is driven by a soft reset from a different clock domain, the inputs to the soft reset can change, leading to asynchronous assertions. Such conditions can lead to potential metastability issues, as illustrated in Fig. 1 where the Tx flop and Rx flop reside within the same asynchronous reset domain, but the TxRstReg (a soft reset) is influenced by changes in a different clock domain.
Conclusion
The growing intricacy of SoC designs necessitates a refined approach to handling resets, particularly with the increased use of asynchronous and soft resets. Proper management and verification of RDC paths are crucial to prevent the myriad risks associated with reset-induced faults. By employing a rigorous RDC verification methodology, designers can significantly mitigate the risks of metastability and ensure the reliability and safety of their SoC designs, ultimately leading to more robust electronic products. This field continues to evolve, highlighting the need for continuous innovation and adaptation in verification techniques to keep pace with ever-increasing design complexity.
To learn more about how soft resets can introduce metastability and how our new systematic methodology can help you resolve these issues (including test case results), kindly download the full paper Techniques to identify reset metastability issues due to soft resets.