Polarion’s R&D Goes DevOps

Polarion’s R&D Goes DevOps
by Nick Entin – Software Engineering Director, Polarion ALM, Siemens PLM
A behind-the-scene look at the development of Polarion.
In this 2 part blog post series, we will take a deep dive into Polarion R&D’s processes and best practices in regards to DevOps.
Many years back, I wrote a set of “Polarion Goes SCRUM” articles. At the time, the Agile methodology was not yet mainstream, and the use of tools like Application Lifecycle Management (ALM) was not common practice. Since then, we’ve learned how to leverage our Polarion expertise and ALM experience to optimize our processes and best practices.
In part one we will focus on the transition of the R&D Team to DevOps.
In part two we continue where we will focus on how we “drink our champagne”, how we utilize Polarion’s capabilities to build Polarion for you!
Background
The term ALM has started to lose its luster of late. Analysts have even begun to replace it with phrases like EAPT (Enterprise Agile Planning Tools) and SLM (Software Lifecycle Management). This has reduced the traditional domain of the more generic ALM.
There’s a lot of talk about how DevOps isn’t considered a native component of ALM. Some go as far as suggesting that there’s no need for ALM at all and everything can be done via popular DevOps tools like GitLab or GitHub.
In my opinion, DevOps is a natural component of ALM and it’s just a matter of how well an ALM tool implements the DevOps domain and integrates with its established solutions.
I’ll outline several scenarios we’ve addressed internally in this area that you can easily implement in your production environment today.
The Scenario
Let’s start with the/our problem statement
We have:
- A complex product.
- The Release Cadence is known in advance and must be followed.
- Every release should have functional and quality increments.
(Substantial enough to be of value to our customers.) - A continuous demand to not only change or adopt a new architecture but also to update the UI. (So that it aligns with other Siemens products and implements the best UI practices and components to maximize usability.) A bunch of Scrum teams integrate different components to the product line and must continually be aware of crossover dependencies.
- Cross-product maintenance tasks (improvements, defect fixing, performance and scalability improvements) that typically affect many areas of the application. They are not the responsibility of a single team, and their impact on the codebase can be far-reaching.
- Continuously changing prioritizations (new/funded projects, customer escalations and estimate changes) that may lead backlog reprioritization, etc.
We need:
- An infrastructure that allows several teams to work in parallel without disturbing each other, especially during the integration phases.
- The system should be able to track how the execution of multiple topics progresses. (For both reporting and synchronization purposes.)
- Each developed feature should be thoroughly tested. (First locally by the development team, then again after integration. This ensures the general stability of the release and eliminates possible regressions.)
- Multi-level integration of the source code should still provide traceability between tasks/requirements and the code. (Enables the code review process and ensures that all changes can be audited.)
- A useable collaboration platform so that teams can effectively consult with each other, Support and Services. It should help facilitate:
- Discussion threads with an easy way to find notes and conclusions.
- Able to request and receive specific expertise from the entire community.
- Customer-on-site support. (For us, it typically means having a Product Manager and/or Product Owner continuously available for ad-hoc consultancy.)
- The possibility to report the progress continuously and without much time overhead.
The Big Picture
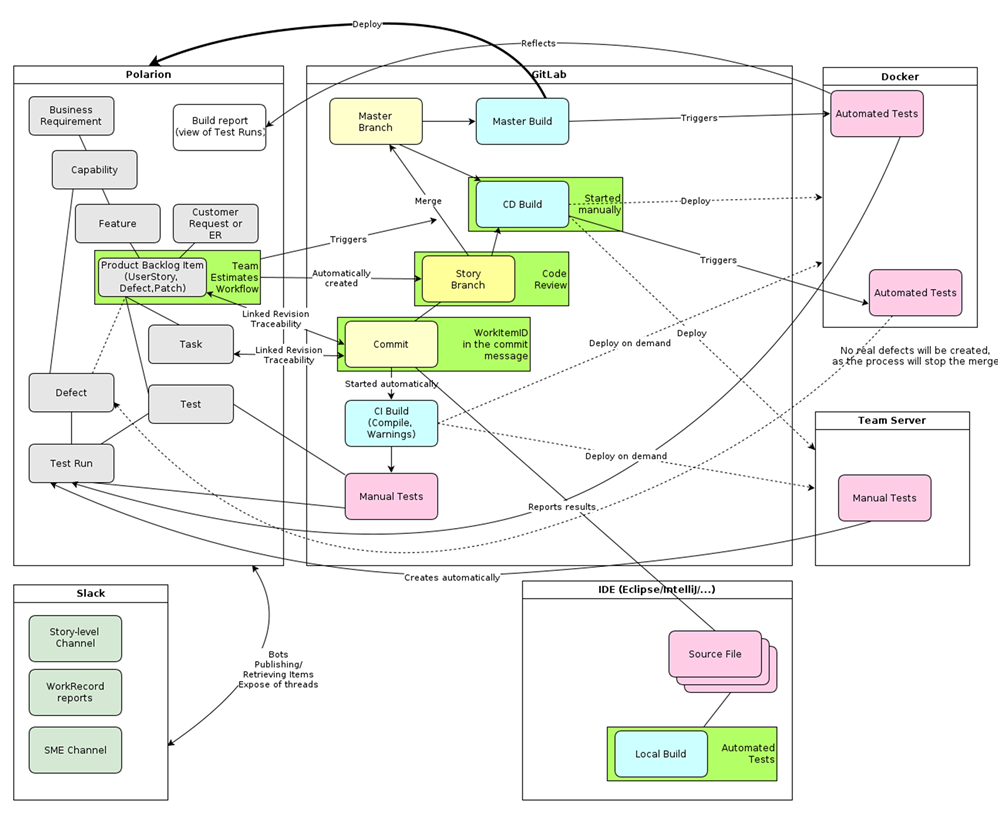
Our toolset & infrastructure
Polarion – central-access-point:
- General process orchestration
- Artifacts (requirement documents, stories, tasks, defects, tests, etc.) lifecycle management, including the full traceability of changes and workflow as the standard operating procedure (SOP) driver.
- Estimation, prioritization and planning
GitLab – build management and a Continuous Integration, Continuous Delivery/Deployment (CI/CD)infrastructure:
- Branching and merging
- Compiling and building
- Test automation execution
Hardware and Software virtualization:
- A set of servers and containers for local and global test environments.
- Team-specific test servers
- Version-specific reference servers. (To reference, for example, how a feature worked in a specific past product version or to replicate an issue.)
- Monitoring, auto deployment, etc.
Development/engineering tools. (Here’s just a few for a reference):
- Java IDEs (Eclipse, IntelliJ, VisualStudio, etc.)
- Profiling tools and frameworks (JProfiler, etc.)
- Test automation tools/frameworks (Selenium, Junit, Cucumber, etc.)
- Documentation tools and frameworks (X-cat, Oxygen, Jabber, etc.)
Collaboration tools:
- IM (Slack, MS Teams, etc.)
- Filesharing (OneDrive, SharePoint, etc.)
Dive In
A quick guide to the terminology and main artifacts of our product life cycle.
Business Requirements
Every good product comes with innovative ideas and proposals on how to address existing or projected customer needs. These ideas come from a variety of sources. From creative team members who think of something completely new, sales teams who collect data and requirements from customers, or Service colleagues who know how to improve existing functionality or implement established solutions in the real world.
The Business Requirements are typically represented by a set of documents describing the problem statement and a proposal of what needs to be addressed.
These requirements will be implemented in our environment following the SAFe framework and by utilizing Scrum/Kanban on the team level.
The Scaled Agile Framework (SAFe) is a knowledge base of proven, integrated principles, practices, and competencies for Lean, Agile, and DevOps, allowing big enterprises to idealize, plan and execute on big projects that may have dependencies, business constraints, and so on.
Capabilities
A Capability is a higher-level solution behavior that typically spans multiple Agile Release Trains (ART). Capabilities are sized and split into numerous Features to facilitate their implementation in a single Program Increment (PI).
A typical Capability in our context will be a significant portion of functionality, e.g., related to a particular domain or commonly used set of services and framework, or a new architecture approach.
Capabilities get grouped into Epics to allow for an even higher level of aggregation and strategic planning. An Epic is a container for a significant Solution development initiative that captures the more substantial investments within a Portfolio. Due to their considerable scope and impact, Epics require the definition of a Minimum Viable Product (MVP) and approval by the Lean Portfolio Management (LPM) prior to implementation.
Epics and Capabilities typically require the most attention from top management, Product Management, and Dev Leads. They’re where the budget across the teams should be aligned, corresponding capacities given, the execution plan drafted, and the risks identified. Very often the Capabilities are not linked directly to a customer commitment, but they serve as a platform for the implementation of many of the Features described below.
Features
A Feature is a service that fulfills a stakeholder’s need. Each feature includes a benefit hypothesis and acceptance criteria. A Feature is sized or split as required so that it can be delivered by a single ART in a PI.
For us, a Feature may represent a business case. (A sellable, functional, and self-efficient implementation.)
Customer Request or Enhancement Request (ER)
These items are recorded when a business customer requests the enhancement of existing functionality. Typically, they are usability or functional additions to what was delivered out of the box and should increase productivity. These items are prioritized by both Support and Product Management then added to the development backlog.
Product Backlog Item
A Product Backlog Item is anything in our process that must be scheduled in a Sprint. User Stories, Product-wide Defects, and Patches are all Product Backlog Items. We initially referred to all of them as User Stories, but as our process evolved, we split them into additional categories because different stakeholders prioritize different things. For example, Defects are triaged and prioritized by a committee. Once that’s complete, the team’s Product Owner determines an appropriate Sprint priority. Patches on the other hand are decided by Product Management. Once decided, patch creation and distribution to customers typically fall to a team. (This team might not have had any involvement in fixing the Defects addressed by the Patch.)
A User Story is the most widely used Agile item for capturing needs and requirements. Its purpose is to capture the natural conversation about what needs to be built into the product from the user’s perspective. It should initiate and track the discussion between whoever wants the Feature and the developers tasked to build it. It’s essential that devs understand the Feature’s intended use and create the best possible solution within architectural and technological boundaries. When the development team understands why a user wants it and what the user wants to achieve, they can come up with a set of possible solutions.
Task
A Task is a piece of work that brings the User Story towards its implementation. Usually, several Tasks are created for a User Story to identify how much of a team’s involvement is required and whether other parties (like documentation and UX) should be involved in the Sprint.
Test
Apart from the Definition of Done and the acceptance criteria of a User Story, a set of Tests can be defined to provide repeatable evidence that a delivered functionality works as intended. (In both the current and potential future contexts.) Many of the Tests are written in code (test automation) and do not require individual authoring as a Work Item for a User Story. However, when the automatic Test is executed, the corresponding object is automatically created, and the execution results are tracked in Polarion for each Test Run.
Test Run
A collection of tests that are executed to prove that a selected product area functions correctly.
Outline
This is the outline of how we approach software development at Siemens Polarion. Stay tuned for part two of this series where I will take you through our planning process inside Polarion and how we do Continuous Integration (CI) and Continuous Development (CD).
Nick Entin
Software Engineering Director, Polarion ALM, Siemens PLM
Do you have ideas or are willing to share your experience – go to Polarion’s Community site: www.polarion.com/community
Comments
Leave a Reply
You must be logged in to post a comment.
Transitioning to DevOps was a game-changer for our R&D team, enabling parallel development, better collaboration, and continuous progress tracking for efficient releases. ccsp training
artcastings is committed to creating products that enrich the spaces where we live and work by crafting high quality pieces rooted in heritage values, innovation, and expert craftsmanship. Artcastings specializes in designing and producing Brass Embellishments, Brass Handles, Wall Murals, Partition Grills, Thresholds, Name Plates, Main Doors, and Pooja Doors. Each item is meticulously crafted using a range of inventive materials, blending traditional and contemporary styles to create truly unique and timeless designs executed by skilled artisans.
A great read on how Polarion’s R&D embraces DevOps to boost collaboration, efficiency, and delivery. The integration of CI/CD with ALM tools is especially impressive. Would love to hear more about challenges faced during the transition! Azure Training in Hyderabad
good keep posting this type of content
data science libraries in python
Really insightful post! 👏 I love how you’ve detailed the transition from classic ALM workflows to a more DevOps-centric model. The way Polarion remains the “central-access-point” for artifacts and traceability, while GitLab handles CI/CD, shows a smart hybrid architecture. https://promptacademy.in/prompt-engineering-course-in-hyderabad/