Libraries – a good way to promote embedded code reuse?
As any software developer is well aware, the basic process for building an embedded application is quite straightforward. Normally, the code is written in some combination of C [perhaps C++] and assembly language and distributed across a number of files [modules]. Each module is compiled/assembled to produce a relocatable object module; this file contains the machine code instructions for the target processor, but with the memory addresses left open. The numerous object modules are then joined together using a linker [sometimes called a linker/locator], which resolves the memory addresses to the required final locations and produces the absolute file, which is an image of the final system memory.
That is the simple picture. There are other nuances, like incremental linking [where a number of relocatables are joined together to make another relocatable – linking, no locating] and object module libraries …
The word “library” is widely used, mis-used and abused. But an object module library is a fairly well-defined entity. It is a file containing a number of relocatable object modules, linked together in a special way so that the linker can extract just those that are required. The normal use of a library is to resolve symbols [normally function names] that have not been satisfied by the relocatable object files. So, if your code calls fun() and this function is provided in another relocatable object file, all is well. If fun() is not found after all the object modules have been processed, it will be sought in any libraries that are provided to the linker.
So, what is the point of a library file? Why not just link all the relocatable object files and be done with it? You can do that, but there may be functions that are unreferenced and are using up memory unnecessarily. When a linker uses a library, it only extracts the required functions/modules, leaving others untouched.
The main use for libraries is to group together a quantity of re-usable code, which can then be used efficiently. A library may be created by the developer or supplied by tools vendors or software IP suppliers. Building a library for an application can be a good way to work, particularly in a development team where sharing of code makes good sense. A library should be planned carefully so that its contents are logically consistent. Functions in a library should also be designed with reuse in mind: no use of global data, clean, well-defined interfaces, reentrancy etc.
Development tools are generally provided with standard C libraries that contain two types of functions. There are implicit functions, which are called by the code generated by the compiler to provide functionality that might be efficiently shared. Also, there are explicit functions, which are called by the application code, like printf() for example.
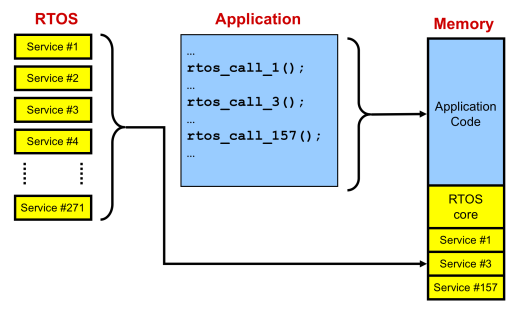
Real time operating systems [RTOSes] are commonly distributed as libraries. This enables them to be automatically scaleable – only RTOS functionality that is actually used is incorporated into the memory image. One issue with library distribution is granularity – how precisely is code extracted from the library? If the library is built from large chunks – maybe a module includes all the functions that work with mailboxes, for example – the linking process will progress very quickly. However, excess code will be included, because a call to the “post to mailbox” function will result in every mailbox function being included, regardless of whether they are required or not. A very granular library might have just one function in each module, which extends the link time, but results in an optimal memory image.
![]()
![]()
![]()
![]()
![]()
![]()