Cutting Fab Costs and Turnaround Time with Smart, Automated Resource Management
By Mark Simmons, Mentor Graphics
Simple in theory, challenging in reality

The competition for market share is brutal for both the pure-play and independent device manufacturer (IDM) foundries. Success involves tuning a lot of knobs and dials. One of the important knobs is the ability to continually meet or exceed aggressive time-to-market schedules. There are a multitude of facets that will enable fabs to hold true to their contracts. Yet, there are counter forces which impede their ability to do so as well, such as hardware and software availability and how efficiently those resources are utilized and consumed, respectively. It is very challenging for companies to always move product out on time. Remember, this not only is an explicit promise to customers, but also represents cost-savings to the fab.
Much of the Mask Data Prep (MDP) flow involves a series of contiguous data processing steps, commonly referred to as jobs or tasks. Traditionally, each job requires a pre-designated allocation of both hardware CPU cores and software licenses to be available for use. If those resources are available, then the job can start as soon as it is launched. But, if they are not available, then the job has to sit in a queue until there are sufficient resources. This time negatively contributes to the total manufacturing time.
Another goal is to free resources so that other jobs may be adequately resourced in order to start. With any multi-threaded, distributed processing software, there’s an inherent penalty in terms of how many of the CPU cores are actively being used at any given time over the lifetime of a job: as work-to-be-done decreases, so does the number of actively processing CPU cores. More and more CPUs become idle, and they cannot be disconnected from that job to be used elsewhere. This inefficiency is associated with every job and when summed up across all jobs in a cluster, it can result in a compounded loss of CPU cores and software licenses that could have been more efficiently and effectively used.
To overcome the delay in launch for jobs and the underutilization of cluster resources, fabs can invest in software targeted to making this production flow more efficient. It dynamically alters multiple jobs’ resource allocations over time as a function of each job’s specific need for resources. This allows jobs to start with fewer resources, which lets them be launched earlier from the queue. It ensures that unused resources are returned to the cluster pool for consumption by other jobs. In doing so, it effectively maximizes the resource utilization across the entire cluster for all jobs. By performing this dynamic resource allocation and from a cluster-level perspective, it is expected that more work can be done in less time with the same number of resources. And doing more work helps to better ensure meeting of schedule for the fabs.
The theory was given proof in a paper delivered at the SPIE Photomask Technology conference (February 2013) in which the manufacturing gurus at SMIC and Mentor Graphics describe how they achieved a nearly 30% aggregate TAT improvement and a greater than 90% average utilization of all hardware resources.
SMIC’s goal, like all fabs, is to ensure continual improvement in its turnaround time (TAT), which is challenging given that newer technology processes are never less complex, and consequently never faster to process. SMIC and Mentor analyzed runtime data trends at the 65nm and 40nm technology nodes and it appeared that they could significantly reduce TAT through improvements in hardware and software utilization. This seems like low-hanging fruit, but considering the challenge of managing the resource allocations for tens to hundreds of jobs simultaneously to obtain this benefit, it isn’t easy.
So Mentor and SMIC devised an experiment. Rather than focusing on tuning OPC recipes or other typical approaches to TAT reduction, they focused on dynamic resource allocation. They used a new resource cluster manager to automatically govern the hardware and software resources for all jobs running on a remote compute cluster. This software solution automatically provided idle resources to jobs that could use them, and revoked resources from jobs when they were not being used. In addition to managing a single task’s allocations, it also improved the utilization efficiency of resources at the cluster level, considering all tasks together as a whole. The experiment showed that when you optimize the distribution of resources to all of the jobs running simultaneously on the cluster you get overall aggregate runtime performance improvement and maximum utilization across the cluster resources.
Foundries are constantly improving their processes in order to cut TAT and be more competitive. Adopting smart, automated resource management is a simple and effective strategy.
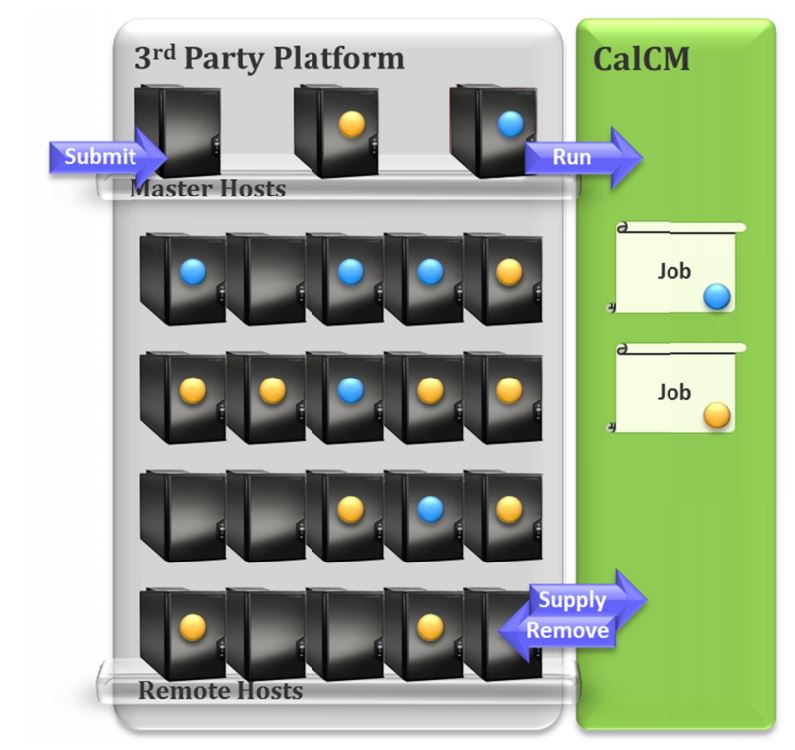
Figure 1: Calibre Cluster Manager (CalCM) automates the allocation of compute resources in the post-tapeout flow.
Author
Mark Simmons is a product marketing manager for the Calibre Manufacturing group at Mentor Graphics with over 10 years of experience. He holds a bachelor’s degree in Physics from S.U.N.Y. Geneseo, a master’s degree in microelectronics manufacturing from Rochester Institute of Technology and an MBA from Portland State University School of Business.
The article was originally published on www.semimd.com