Visual Language Models: Turning design chaos into order

Imagine a future where engineers no longer navigate through endless CAD models, manually identifying each part and each component for simulation setups or design refinement. Vision-Language Models (VLMs) are redefining this reality. Combining the powers of visual perception and natural language understanding, VLMs offer an approach to model analysis by “looking” at parts. But what exactly is a VLM, and why should engineers care?

What is a VLM and what is it for?
A VLM is an AI system that combines language understanding with visual perception, allowing it to interpret images and comprehend text simultaneously. A VLM is often built upon large language models (LLMs) for its advanced language processing capabilities.
In recent years, VLMs have experienced significant advancements, evolving from basic object recognition to intricate reasoning about complex scenes, understanding lengthy videos, and even interacting with physical environments. A notable example is a VLM-powered robotic system by Gemini Robotics, where Google DeepMind demonstrated the capability of planning and executing detailed manipulation tasks, such as grasping a mug by its handle, using only visual input and natural language instructions. This showcases VLMs’ ability to not only recognize objects but also achieve a deeper understanding of the environment.
Tech giants are investing significant resources in VLM research, exploring a wide range of applications — including autonomous driving, document understanding, real-time video analysis, and embodied AI. Researchers are pushing towards generalization, empowering models to handle scenarios they’ve not been explicitly trained on. As models improve in perceiving and reasoning about diverse visual contexts, the barrier between “seen” and “unseen” tasks begins to blur, opening the door to AI systems that adapt fluidly to new challenges.
Role of VLMs in the Preprocessing phase of the simulation process
It is widely acknowledged among simulation experts that geometry preparation constitutes the most time-consuming phase of Computer-Aided Engineering (CAE) analysis. This critical preprocessing stage often involves significant time spent remodeling geometry to resolve inaccuracies or reduce complexity. Such efforts are essential to ensure the model is suitable for subsequent simulation steps.
Inaccuracies like gaps or sliver surfaces, or excessive complexity from irrelevant features such as blends and fillets, can severely impede the meshing process. These issues not only complicate mesh generation but also increase solution times, highlighting the necessity of a clean and optimized CAD model. Therefore, careful geometry preparation is primary for effective and efficient CAE analysis.
Consequently, engineers frequently dedicate substantial time, often days or even weeks across design iterations, to these tedious geometry cleanup tasks. This repetitive and time-consuming effort in preparing models for analysis is precisely why simulation experts consistently identify geometry preparation as their most challenging and resource-intensive activity. Streamlining this phase is crucial for accelerating product development cycles.
VLMs have the potential to significantly enhance the preprocessing step by quickly and accurately classifying parts, driven by natural language prompts. Having a VLM assistant for the task of parts identification and part classification would accelerate the preprocessing phase and ensure a higher degree of accuracy in the preprocessed model.
To illustrate this transformative potential, we have developed an experimental system that extends standard metadata filters, showcasing a powerful search use-case and the remarkable generalization abilities of VLMs. Our experimental system enables users to intuitively search for parts based on both their topological form, considering shape, geometry, and structure, as well as their functional attributes, understanding what the part is designed to do. For instance, prompts such as “Show all ring-shaped objects” guide the model’s attention to specific shapes, while requests like “Find fluid storage tanks” or “Highlight components used for sealing” leverage the VLM’s capacity to interpret function from visual and contextual cues.
This advanced VLM approach liberates engineers from the constraints of rigid part names or predefined metadata. It enables the system to infer meaning and intent across unfamiliar datasets, effectively surfacing relevant components even if they are labeled differently or have never been encountered before. Such inherent flexibility proves invaluable for comprehensive model exploration, precise component identification, and refining complex simulation setups, particularly when dealing with intricate or legacy assemblies.
The current state of capabilities: Are VLMs ready?
The world of VLMs is a rapidly evolving landscape, with significant investments from tech giants constantly pushing the boundaries of what’s possible. While the pace of innovation means that what was challenging last year might be routine today, the results we present here offer a snapshot of their current maturity, a benchmark where these powerful tools stand right now. We’re already eager to revisit these evaluations in a year to witness the next leap in their capabilities!
Our assessments, summarized in the illustrative table below, highlight the performance of commercial and open-source VLMs in identifying a diverse range of mechanical parts. For clarity, we’ve used generic labels such as “Commercial VLM” and “Open-source VLM” for proprietary models. This table represents only key findings from our broader evaluation across four distinct datasets, one of which includes customer data.
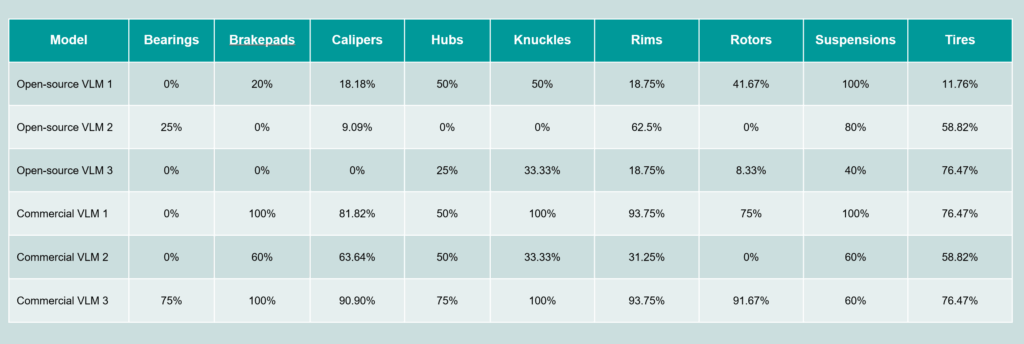
It’s important to understand that a low or even 0% accuracy score doesn’t always signify a complete failure of the model to “see” an object. Instead, it often indicates that the VLM has correctly identified a part but perhaps under a different, yet valid, name or label than what was expected in our specific test. Despite these nuances, commercial models consistently outperform their open-source counterparts, demonstrating remarkable accuracy across a wide range of components, from basic clamps and bolts to intricate automotive assemblies, such as brake pads and suspensions.
Often, the VLM’s ‘mistakes’ are not fundamental misidentifications but rather a matter of semantic precision or specific terminology, as seen when it provides a closely related or functionally similar label, for instance, identifying a ‘nut’ as a ‘ring’ or a ‘pulley’ as a ‘wheel’. This is a positive sign, as such nuances are highly amenable to improvement over time as VLM technology advances, and can often be refined through targeted fine-tuning with domain-specific datasets. This suggests that with further development and strategic customization, these models are well-positioned to achieve even greater accuracy and align perfectly with expected terminologies.

Although these results underscore the strong capabilities of commercial VLMs, it is essential to emphasize that determining whether these models are suitable for production requires a careful evaluation that considers cost, computational requirements, and long-term viability. Out-of-the-box performance shows promising results; however, their high implementation costs remain a significant factor, necessitating further investigation into making VLMs more cost-efficient and practical. While we are optimistic about their potential, the journey toward production use is ongoing and will continue requiring rigorous assessments to ensure they align with real-world production goals.
Looking into the future
In conclusion, VLMs are truly revolutionizing the way we approach and automate engineering workflows. Their ability to seamlessly analyze visual and textual information presents enormous potential for tackling some of the most challenging aspects of engineering, such as time-intensive preprocessing tasks and geometric preparation for simulations. By leveraging the powerful generalization and classification capabilities of VLMs, we have demonstrated how these models can enhance part identification, streamline workflows, and ultimately save engineers valuable time.
We are thrilled about the progress we’ve made today, as our prototype showcases the promising, transformative impact VLMs might have on managing complexity in engineering design. However, this is just the beginning. With rapid advancements in AI technologies and the continuous evolution of VLMs, these models hold the promise to unlock numerous possibilities, delivering even greater breakthroughs in the years to come.
Stay tuned with us as we continue to explore and innovate in this exciting space – the journey of turning design chaos into order has only just begun!
Special thanks to Roberta Luca, Omar Al-Hinai, Dragos-Dumitru Stanica, Viorica Puscas, Cosmin Ivan and Evelina Popa for bringing their technical expertise to this project.
Disclaimer
This is a research exploration by the Simcenter Technology Innovation team. Our mission: to explore new technologies, to seek out new applications for simulation, and boldly demonstrate the art of the possible where no one has gone before. Therefore, this blog represents only potential product innovations and does not constitute a commitment for delivery. Questions? Contact us at Simcenter_ti.sisw@siemens.com.