AI Foundations: Modeling a Neural Network

Understanding the building blocks of artificial intelligence.
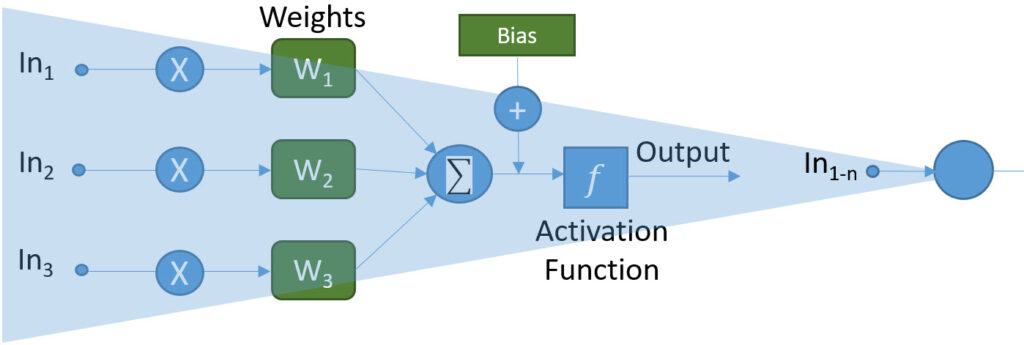
Previously we saw one way to model the human neuron. That is a pretty exciting accomplishment, but we soon saw the limitations of a single neuron in terms of AI. What we need to do now is connect these neuron models together in some way to form a neural network. To do that, we start by conceptually condensing the neural model down to a single node. The input number can scale from 1 – n, all the functionality still exists in the node (with one exception), and a single output is available.
A simple neural net is typically modeled as a connection of single neuron nodes within an acyclic graph where the output of a neuron is connected to the input(s) of another neuron. A simple neural network moves data forward and there are no cycles between the same neuron. Neural nets are typically specified in rows of neurons called layers. The main rule of a forward-connected network is that each neuron output in the layer can connect to every input of the adjacent neurons in the next layer and there are no connections to neurons in the same layer. The following figure shows the possible connections between the first neuron in the input layer to the first neurons in each layer in the network. These connections model the synapses in the human brain.
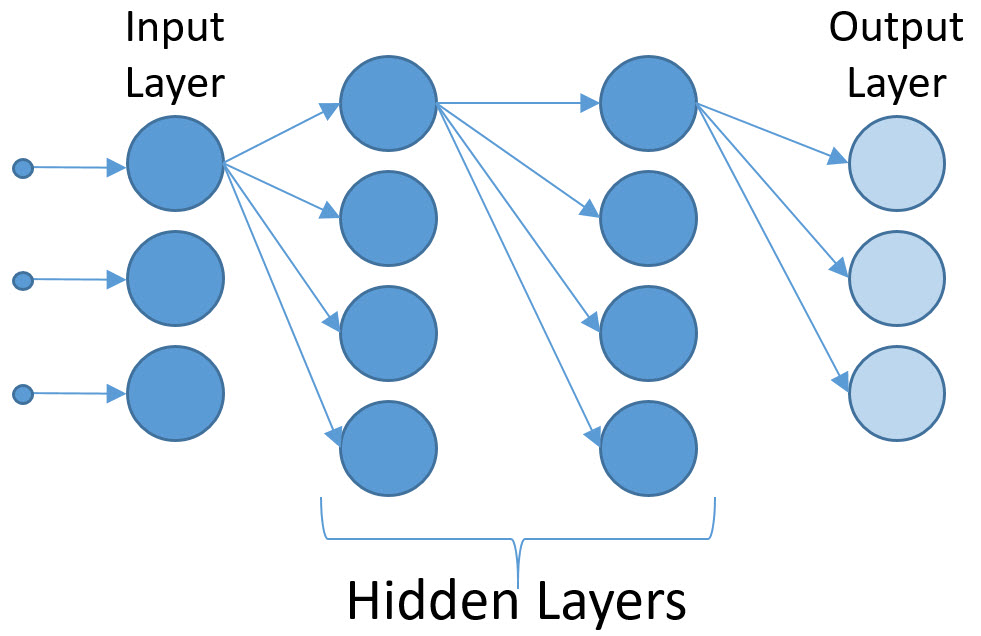
The world of neural networks, as in any science, is built on defined terminology. Perhaps the most confusing term is “hidden layers.” In our network model so far, the two rows of neurons between the input and output layer are hidden layers. They are called hidden because there is no direct connection between the neurons in these layers and both the inputs and outputs. However, in a software model, these layers are obviously specified and not really hidden. The hidden layers do the “heavy lifting” within the network.
Neural networks are typically named after the number of layers in the network, like “2-Layer Network.” Yet again, this is a bit misleading, as the input layer is not counted. So, our model is a 3-Layer Network. And, there is one more twist. The neurons of the output layer do not contain an activation function, as their job is to represent some kind of numerical score in relation to the actual value that is being targeted. Here is the fully connected neural network:
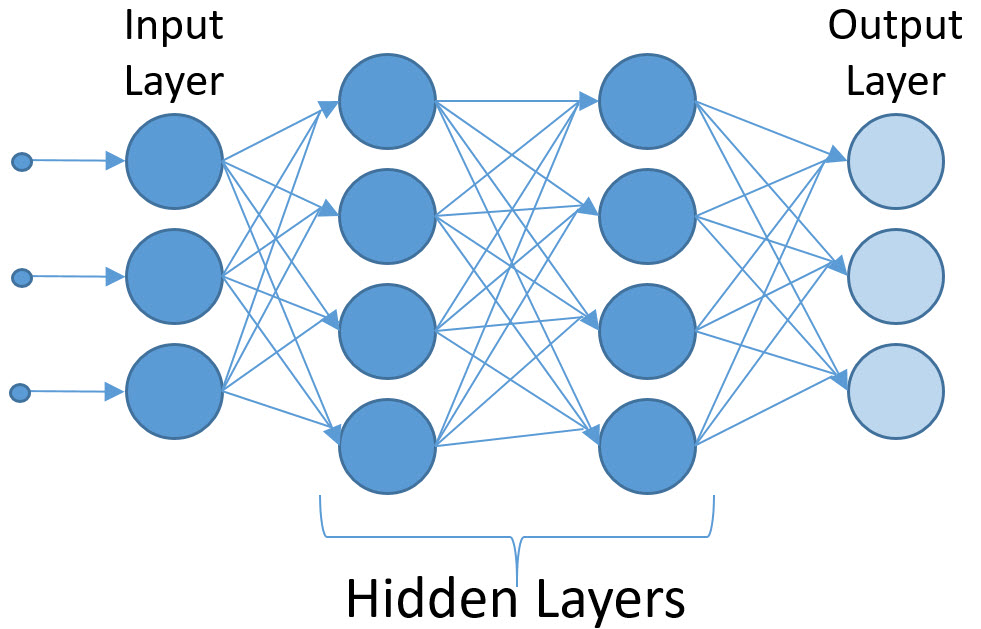
Seeing a neural network for the first time inspires the logical question: how many neurons should an AI application employ? After all, the human brain has over 80 billion of them. Perhaps, our model should use as many neurons as possible? It turns out, this is not correct. In fact, experiments have shown that the number can vary depending on what the AI function is trying to accomplish and on the dataset being analyzed. Calculations within the model all expend energy, so if the AI function is implemented in hardware, power consumption becomes a concern. Typically, the number of layers and the number of neurons in each layer are variables that designers adjust to get the results that they desire. Designers also examine each neuron during the training process to see if they can trim away neurons that have little impact on the AI application in order to optimize the network.
After the neural network structure is in place, what can it do? Not much, until it is trained using data. We will cover that topic next.


