Exploring AI and machine learning: the transcript

Previously, I summarized Episode 1: Exploring AI and machine learning, where our experts Ellie Burns and Mike Fingeroff discussed why AI and machine learning (ML) was turning up everywhere. For those that prefer reading instead of listening to the podcast, here is the transcript of this episode:
Mike Fingeroff: Hello, everyone! I am Mike Fingeroff, a technologist with the Catapult High-Level Synthesis group – and today we’re going to be talking about artificial intelligence and machine learning basics. And with me, I have Ellie Burns. Ellie, why don’t you tell us a little bit about yourself?
Ellie Burns: Hi! Thanks, Mike! I’m Ellie Burns. I’ve been in EDA and the electronics industry for almost 30 years now. My roles have ranged over many different aspects, but mostly focusing on the hardware and ASIC and the FPGA design. So, really, we’ve come into AI and ML more on the hardware design side. We are exploring what kinds of compute resources it takes to implement AL and ML hardware solutions.
Mike Fingeroff: So Ellie, everywhere we look today, people are talking about artificial intelligence and machine learning. And, we’re seeing it deployed across many industries and applications. Why is AI and ML becoming so pervasive now, when it’s been around for 70 years?
Ellie Burns: I think it’s a really interesting question because if you look back at the history of AI and ML, it was invented back in the ’50s. So, you might say, “Okay, well, that’s not new!” So, what’s different? What’s happening now? And I would say, basically three things are different now. One is the compute resource; two is the amount of data; and three, the algorithms. So, let me expand on that a little bit more.
For compute resources, we didn’t really understand how much compute power was really needed to run these kinds of algorithms. Scientists thought, “Well, we need the supercomputers of the day”, or “I can run this on various racks.” But it quickly became evident that these algorithms needed a huge amount of compute resources. An example – and I’ll expand on these examples as we go through this and talk about the different neural networks. A very popular network now, one that started it all, is a network called AlexNet, created back in 2012. It took six days to train this network on two high-end NVIDIA GPUs. That would be weeks on a normal computer, maybe months. So, scientists vastly underestimated the required compute resources. Even today, we look at a network that I’ll talk a little bit more about – RESNET 50 – that takes 14 days to train the network. So, these kinds of compute tasks, back 20 years ago actually wouldn’t have even been possible. They would have consumed years in CPU time. So, there’s a lot of research to continue to make that faster and faster but be aware that the compute resource for these is ginormous!
The second thing is the data. We had different kinds of data sets where we had different images or voices. But now, with the advent of all of the photos that are online, we have this huge data set. I want to refer to one kickoff moment, which was a data set called ImageNet in 2009. This data set this was built by Fei-Fei Li and her very small team. It’s real fascinating work that she presented in a small corner of a conference. It consisted of 3.2 million labeled images in over 5000 different categories. And this idea of having an image with a label on what it was the key. At that time, millions of images could take months of CPU time. Now, we’ve got all these different databases that are coming from things like Amazon reviews. Natural language processing can analyze Amazon reviews. So it’s got millions and millions of Amazon reviews – all of this is online. Or Google now has started Open Images, which has 9 million different images. In AI and ML it’s all about the data. This data is driving these models, enabling scientists to experiment with their models and algorithms.
Ellie Burns: And then the last thing is really the algorithms. These are improving at an exponential scale. It’s really exciting for me, as long as I’ve been in this high-tech industry to see such rapid evolution of changes in algorithms and hardware. The compute costs have gone down, we have new data sets, and now, all of the algorithm developers have both of those things as a platform to support new algorithms. Just a quick example of rapid algorithm improvement is the ImageNet challenge that took place between 2010 and 2017. The winning algorithm went from 71% accurate – which is not near-enough accuracy to actually do AI – to 97.3% accurate in just that short seven-year period. That is a really incredible advance! I’d say probably one of the really defining moments was in 2012, where this deep neural network called AlexNet was seen as a catalyst to start the boom of the AI industry. So, if I think back on where things really made a difference, and it is the three elements propelling us forward today. AlexNet was the spark for that amazing accuracy, to say, “Okay, I’m not just recognizing characters and ears on a cat. What I’m doing is I’m training the computer to recognize the pieces.”
Mike Fingeroff: That makes a lot of sense! I can see the need for compute power simply because, as you mentioned, with having to process millions of images, just knowing it from an image processing background that that’s an incredible amount of compute complexity that you’re going to need to implement these algorithms. So, along with that, we hear a lot of buzzwords today that are getting thrown around when people are talking about AI and ML. What exactly are deep neural networks? And what does it mean when someone says it’s either a convolutional neural network – where they abbreviated it as a CNN – or a recurrent neural network, which was abbreviated as RNN?
Ellie Burns: That’s a great question! I’ll start with the definition. You’re going to hear AI – artificial intelligence – and machine learning, which is training the machine to be intelligent. And then, the implementation of that is a neural network. In the case of a deep neural network, the neural network is really an algorithm that’s loosely modeled on the brain. I don’t know if you’ve ever studied how our brain works? Our brain has all these neurons that fire and they’re connected with different connections. For example, the human brain tries to detect some sort of pattern. A deep neural network – like AlexNet, which I referred to a little bit earlier, is a convolutional neural network – is really a collection of neural networks. Think of these as layers that are stacked together. When you hear a reference to a deep neural network, then it’s got basically more than a couple of layers. And each layer is really looking for something specific in an image. I am talking about image classification. For example, in the Alex Neural Network, if you’re looking for cats, one layer might be looking for cats’ ears, another layer might be looking for whiskers, and another layer might be looking for the tail. All of these different layers are trying to break apart the image and detect each of these features. These layers are called feature detectors. They’re then all combined together. And once you combine all of these together, you get a very accurate classification of what the network was looking for.
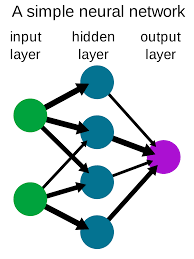
Ellie Burns: The Convolutional Neural Network, which is typically used in image processing, as you said, and the key question is: what is the algorithm at the core? At the core of this network, each of the nodes is really doing a convolution which is a very typical image processing task. A Convolutional Neural Network has convolution at its core and it is typically is doing image processing.
Ellie Burns: Other types of Deep Neural Networks (DNN) have different types of algorithms at the core. So, simplistically, I’ve got different types of networks to perform different types of things and each works on different types of data. Other deep learning networks, such as an RNN, which stands for recurrent neural network, is performing applications such as natural language processing. A different neural network is going to be employed to try to understand language, as opposed to a neural network that’s focused on recognizing cats, dogs, and bikes. In general, neural networks are really computationally expensive with basically hundreds of billions of computations per second.
Mike Fingeroff: Thanks Ellie for exploring AI and understanding how neural networks work today. Tune in to our next podcast where Ellie and I will discuss training versus Inferencing and the role of AI in the industry.


