Ramping up machine learning and vision-based automation with synthetic data

Use synthetic data to accelerate machine learning quickly and easily for vision-based automation systems

Synthetic data is about to transform artificial intelligence. Today, machine learning is used for a variety of vision-based automation use cases like robotic bin picking, sorting, palletizing, quality inspection, and others. While usage of machine learning for vision-based automation is growing, many industries face challenges and struggle to implement it within their computer vision applications. This is due in large part to the need to collect many images and the challenges associated with accurately annotating the different products within those images.
One of the latest trends in this domain is to utilize synthetic data to speed up the data collection and training process. Synthetic data is typically regarded as any data that is generated by a computer simulation.
However, utilizing synthetic data for vision use cases requires expertise in synthetic image generation and can be complex, time consuming, and expensive. In addition, while some techniques and best practices for employing a machine learning model trained with synthetic data in real life already exist, these techniques are not yet commonly practiced.
There needs to be an efficient method to bridge the skills traditionally required for a vision system such that it can be trained and deployed. Such skills include data collection and annotation, machine learning model training and validation, and integration into the complete automation system.
Providing an automated way to address the above tasks is key to scaling up the technology and making it accessible and cost-effective. The good news is that there is a way to do it! Read on to learn how.
By 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated.
WSJ, quoting Gartner Inc.
The potential of synthetic data for machine learning-based vision systems
The AI for machine vision market is expected to reach $25B by 2023 with a CAGR of 26.3% (source MarketsandMarkets). This market consists of industry use cases such as kitting, sorting, picking, shopfloor safety, throughput analysis, quality inspection, and many more. For instance, vision systems utilize objection detection algorithms to automatically recognize the position of objects and guide a robot to pick them up.

What are the steps for object detection?
To understand the potential of synthetic data, let’s review the workflow of deploying a typical object detection vision system:
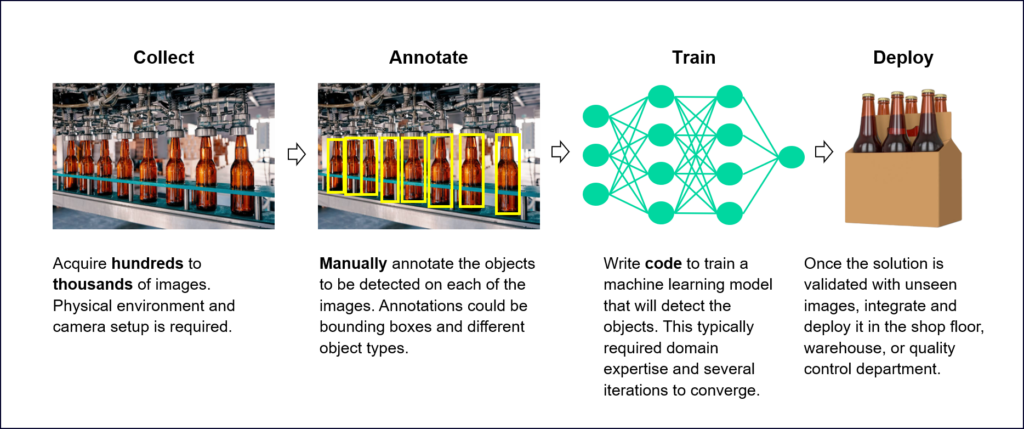
Synthetic data can help with shortening this workflow and making it more robust by addressing some of the pain points in the data collection and annotation stages:
- Data Collection – Theoretically, an infinite amount of synthetic data can be made available without having to set up the physical environment. This is especially beneficial for data-constrained scenarios, i.e., where the amount of real data that can be collected is limited to non-existing, or that it is very hard to obtain. For instance, if an existing manufacturing line must be stopped to collect the training data it could incur potential production losses. Synthetic data can also provide a much larger variation than the one typically observed when collecting real data. For instance, in a virtual 3D environment it is easy to create varying light or other physical conditions while in the real environment there is generally limited control over these parameters. Thus, utilizing synthetic data can improve the machine learning model’s ability to generalize well when deployed in environments that it has not encountered before.
- Annotation – Manually annotating data is often regarded as a repetitive, mundane task. Or, as it was phrased in a recent article by Google Research: “Everyone wants to do the model work, not the data work“. Often, the human workforce that is annotating the objects lack domain expertise or proper guidance and this leads to non-exact or simply wrong annotations. On the other hand, synthetic data is always accurately annotated, as the annotations (bounding boxes, object contours, etc.) are generated automatically based on complete knowledge of how the synthetic data was formed. This reduces annotation errors that are typical in manual annotation projects.
Bridging the gap between synthetic and real
While 3D CAD and simulation tools have been well-established for a long time, recent advancements have made significant progress in transferring capabilities learned in simulation to reality. Those computer vision techniques are commonly referred to as “Sim2Real”.
There are a few existing methodologies for generating synthetic data that can train machine learning models to perform well when fed real data.

All these methodologies fall somewhere on the scale between Close to Real simulation and Domain Randomization.
Close to Real – In this approach, you invest your effort in trying to make the simulation as close as possible to the real expected scenario. Considering a bottle packing line let’s assume you need to perform an automatic vision-based counting of the bottles before capping and shipping them. Some properties are already known before you begin generating the synthetic data:
- Camera properties – exact location, field of view, resolution, etc.
- Lighting conditions
- Bottles and surrounding material properties – colors, textures, reflection, refraction, transparency, etc.
- Possible positions of the bottles in the test station
- Typical noise or artifacts generated due to the camera’s optical and electronic properties
Given some of these properties, you can manually create a 3D simulated scene that mimics many of them.
- Pros:
- The trained machine learning model is likely to perform well in highly similar scenarios.
- The trained machine learning model is likely to perform well in highly similar scenarios.
- Cons:
- Sensitive to changes and perturbations.
- Requires higher effort to accurately simulate the scene.
- Harder to automate or re-use in other scenarios that have even slight variance.
Domain Randomization (DR) – Here you randomize many of the environment properties, from number of objects and their locations, to material properties, camera properties, surrounding environment, etc. When training a machine learning model based on such a randomized dataset, the resulting trained model will know how to ignore the properties that are randomized and focus on the ones that are not (such as the part geometry). This way, the trained model can generalize to various environments and domains, including the real expected environment.
- Pros:
- Can be automated easily.
- Spares precious engineering time.
- Less sensitive to environment changes.
- Cons:
- Requires more data since the randomization causes higher variance (more options for how the environment might look).
- In some cases, the machine learning model will not be able to perform well enough in the real environment and will require some manual adjustment, e.g., set the camera location, field of view, image resolution, and object texture.

- Fine-tuning – A technique we use to take a machine learning model that was previously trained on some dataset for a specific task, and continue to train it on a different dataset, possibly with different parameters and for a different task. After training models purely on synthetic data, sometimes the model can immediately perform well enough with real data. In some cases, depending on the environment and task, the machine learning model may require some fine-tuning using a small number of real (usually annotated) images before it can perform well.
- Domain adaptation (DA) – The ability to apply an algorithm trained in one or more “source domains” to different (but related) “target domains”. In our case, the synthetic dataset is our source domain, and we want to train a model to perform well in real life.
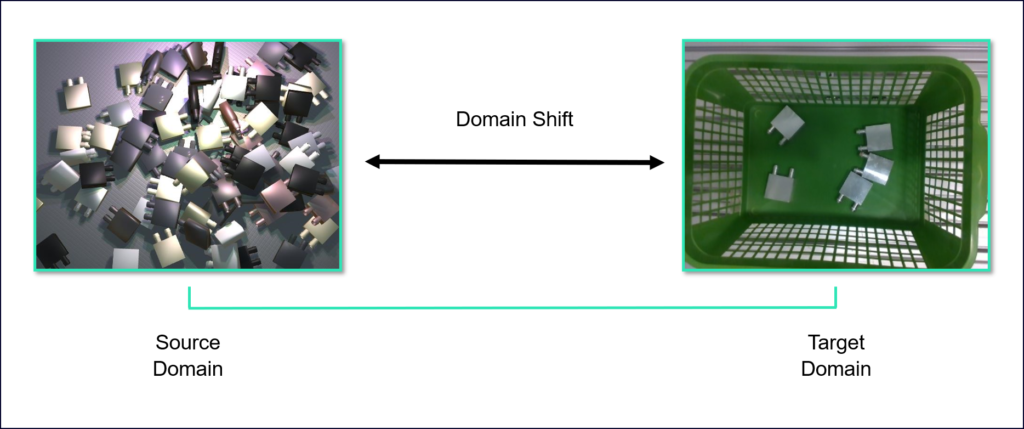
There are several techniques to close this gap (often called “domain shift”). Some techniques use GANs to generate images that appear closer to the target domain. Other methods (like this one) use derivative based methods to generate realistic images. Generally, DA is a wide and fascinating field of research. If we piqued your curiosity, then this blog post can be a nice start.
The challenges of adopting synthetic data for industrial use cases
You can use game engines or simulators, like Blender, Unity3D, Unreal, Gazebo or others, and create a custom 3D simulation for the purpose of generating synthetic annotated datasets. Typically, to achieve your goal using those tools would require specific expertise and knowledge in 3D environments and programming. You need to know how to create your scene, create variance (randomization) between different images, adjust your virtual camera and other sensors, and finally create the images, annotated in the required format.
Besides the expertise required, this process, like any other engineering or development process, takes time. Especially if you choose to model a close-to-real simulation. This can often be extremely time consuming. Sometimes even up to a point where the effort to create the simulation is much higher than the effort to manually collect and annotate the real data.
Finally, even if you choose to create the dataset yourself, you need to create and train it using the correct methodology, in the context of domain randomization, and fine-tuning. For engineers who are not experienced in such methodologies, the training results can be sub-optimal.
How SynthAI™ software helps
SynthAI is a new online service from Siemens Digital Industries Software that is aimed to solve exactly those challenges!
—–

Request SynthAI Early Access
Use synthetic data to accelerate machine learning quickly and easily for vision-based automation systems.
—–
To start using SynthAI you only need to provide a CAD file of your product. That’s it. No more taking hundreds of image samples, no more hours on end of tedious annotation work or tweaking the parameters on your machine learning model. Just upload your CAD file and you’re all set.
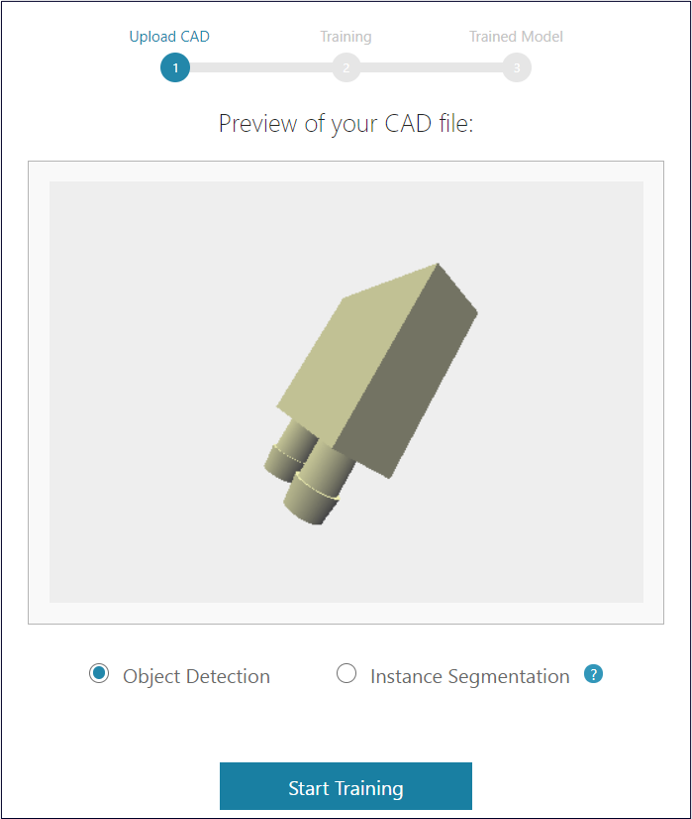
After you upload the CAD file of your product and start the training process, SynthAI will automatically generate thousands of randomized annotated synthetic images within minutes.

But it won’t stop there – SynthAI will also automatically train a machine learning model that could be used to detect your product in real life.
Once the training is done, you can download the trained model so that you could test and deploy it offline. If you’d like to handle the training on your own, feel free to do so – download the complete synthetic images dataset together with the annotations and run your own training.
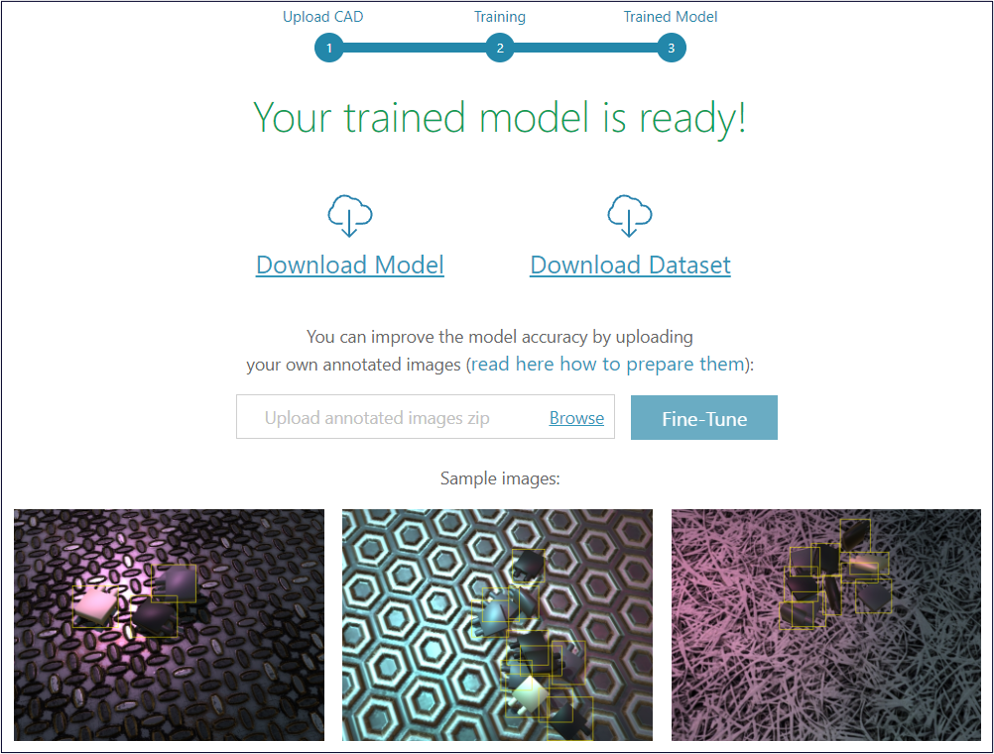
Integrating the trained model into your own project is just a few lines of code away – the downloaded model comes with a complete python environment setup and sample code that lets you quickly and easily use the model to detect the trained product in your images.
Your model doesn’t detect the product as expected on real images? You can improve its accuracy by uploading and annotating just a few real images. You can annotate your real images for object detection (bounding boxes) or instance segmentation (object contours) and then fine-tune your model to become much more accurate.
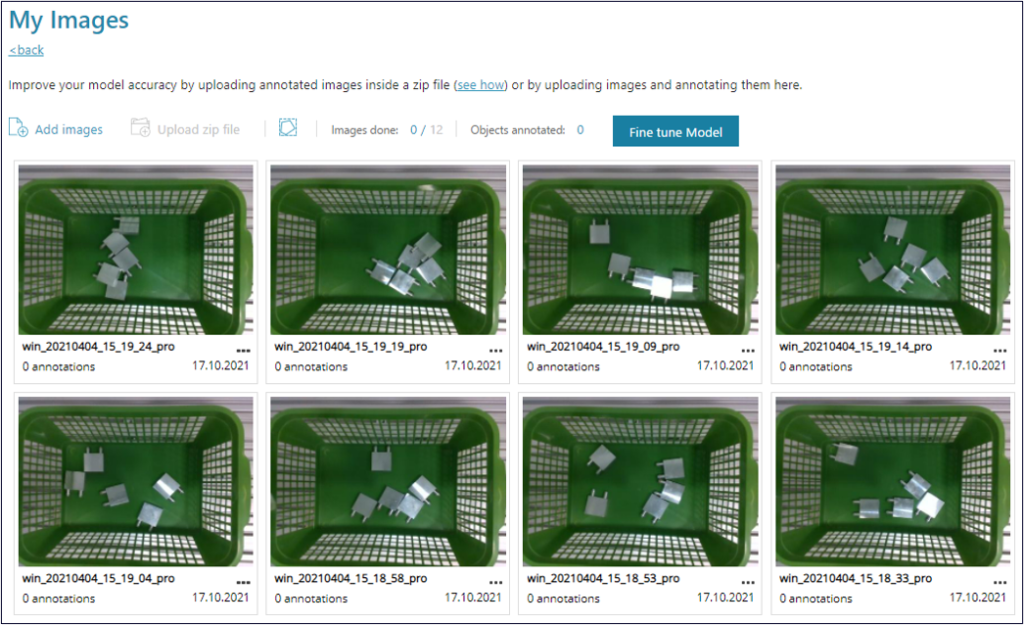
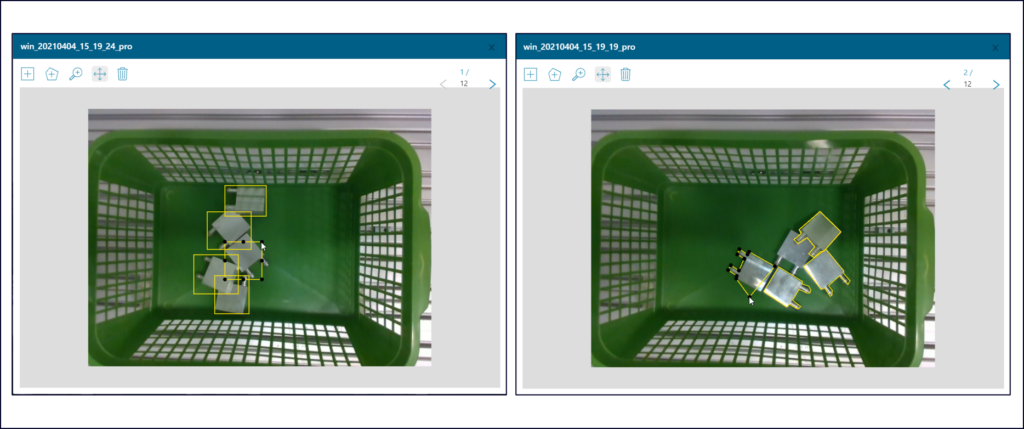
SynthAI is a solution still in the making and we are constantly adding features and capabilities and improving its ability to generate high-quality synthetic images and trained models.
Watch this short video to see how SynthAI can be utilized to train and deploy a robotic product picking scenario:
—–