Model-based Product Safety & Reliability: forward vs backward looking design…
No one seems to notice product safety & reliability until something goes wrong…
Forward thinking Product Safety & Reliability is about moving from isolated reliability and safety analysis processes (including disconnected FMEA tables, Fault trees, etc.) to integrated reliability models that can proactively influence product development towards safe/reliabile products. Which way are you facing?
While working on one project, I was the designee to deliver bad product safety & reliability news in a project review… After the swearing was over, the program manager put it this way, “this is like driving a car looking thru the rear view mirror, I can see the problem after I’ve run over it. Why don’t you give me something I can see it coming so I can avoid the problem”. Since then I’ve been looking for ways to implement forward-design thinking to predict product safety & reliability problems/reduce risk vs. trying to fix them after we’ve run over them (check previous blogs about how a connected product architecture is critical to forward looking design)

Systems Engineering/Product Safety & Reliability engineers are in the business of reducing technical risk, avoiding future problems vs saving money (see different blog/discussion about justifying systems engineering); which is part of our problem since we lack evidence that we are as good as we say we are (see MIT/NSF Research on “Nobody Ever Gets Credit for Fixing Problems that Never Happened” for a good read on this topic).
Yet, when visiting organizations with million(s) dollar mistakes, the people who made the mistakes are still there because you can’t find the evidence that their decisions lead to the problem (It’s like paper training a puppy, you’ve got to catch them in the act)—their decisions are separated by time & space from the consequence (i.e. engineering decision relativity).

The recent headlines of the emergency notification false alarm in Hawaii is a timely case in point, the connection to the person that hit the button was obvious, but who designed a system to allow a single mis-button push to trigger the warning and another way-longer number of minutes to figure out how to retract it (see you don’t know who that is either)? Apple and others have learned their lesson which is why it takes getting through a three (3) deep warning system before allowing you to clear/reset your cell phone—i.e. are your really, really, really sure?
How come we keep repeating the same product safety & reliability problems…
If we accept that bad design/architecture may produce bad results, let’s at least learn from the experience and rather than look for scapegoats, lets at least put a connection between the problem and the root cause so we don’t repeat the problem and maybe even feed it forward to the next project to design a more robust solution. I’ve been keeping a ‘problem resurface metric’ by industry for some time—how long does a problem once solved take to come back:
- High tech: says 6 months
- Auto: says 3 years
- Aero: ~20 years
… all of which seems to match their project cycles and how knowledge (in people’s heads) moves from project to project.
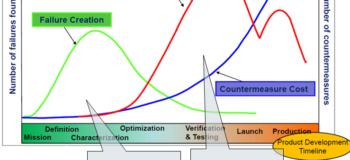
So when I came across this graph:

…which describes the obvious–it’s better/cheaper to catch the problems where we plant them vs after they yield results. Rear-view mirror thinking is on the right side; it uses data that comes from things like warrantee issues or customer complaints to discover problems. Forward thinking on the left requires predictive models. So even though it’s intuitively obvious to catch problems early, since we don’t have a predictive product safety & reliability model of our system (and probably no prior experience with unprecedented systems), we end up looking through the rear-view mirror to discover potholes while driving our projects.
So which way are we facing…
Today’s standard reliability artifacts (FMEA, FMECA,…) are examples of back-ward looking design. For example, many organizations gather a group of product experts in a conference room to discuss various hazards, their probability of happening, potential impact, and possible ways of mitigating the consequences. They will use isolated spreadsheets or FMEA-type tools capture the information. As soon as they leave the room things change, the spreadsheet is not maintained, et al. (if we start with a spreadsheet from the last program, it’s an attempt at forward thinking to apply past experiences to the current project, but it rapidly becomes backward because it’s not maintained in a connected way—so it’s a snapshot of how something was and quickly recedes in the project rear-view mirror). Imagine doing that with a multi-million part airplane with say 3 possible failure modes per part in a spreadsheet (you can’t, according to Microsoft Excel limits are 1,048,576 rows by 16,384 columns).
Now imagine a more scalable forward-looking model-based approach which begins with a product’s functions and where those functions are allocated/performed. This establishes the functional network that can then be used to drive reliability models to be able to predict overall product safety & reliability, areas of concern, and the model can output artifacts as a by-product (FMEA tables, Fault Trees, etc. as an output from the model vs a means of capturing existing product behavior). Plus you now have product safety & reliability impact traceability, so when a change happens you can see where it goes/what it does to your product reliability and you can move toward prognostics-type thinking; i.e. advanced forward thinking (I can see where our visibility/coverage is limited and use that information to add sensors, etc. to improve our coverage to improve our product safety & reliability even more).
This model-based capability is found in PHM’s Maintenance Aware Design (MADe); the only Model-Based Product Safety & Reliability solution) which is in process of being integrated with Teamcenter’s product lifecycle management (PLM) solution. This merges the product architecture and configuration with product safety & reliability modeling allowing us include safety & reliability as an active contributor to daily design decisions– moving you towards a forward looking design environment that allows you to improve product safety & reliability in a proactive way–safe, reliable, secure by design (vs. current disconnected spreadsheets and isolated reliability tools with their periodic wakeup calls from product recalls).
More information is coming as we integrate product safety & reliability modeling solution with the product lifecycle or you can contact your Siemens account manager for details.
–Mark Sampson


