The Data Deluge: What do we do with the data generated by AVs?
This is part two of a seven-part series on the growing importance of automotive software. Click here to read part one, or visit siemens.com/aes to learn more.
For vehicles to sense, think, and act you need state-of-the-art software and advanced computing systems to transform sensor data into decisions in real time. But, how much data are we talking about? Estimates of the amount of data an autonomous vehicle will generate vary greatly. The rate of data generation all depends on the automation levels implemented in the vehicle.
The Society of Automotive Engineers (SAE) defines six levels of sophistication for autonomous vehicles, from zero to five (figure 1). A car with level two autonomy may feature active cruise control, a lane departure warning system, lane keep assist, and parking assistance. In total, this car requires about seventeen sensors to enable its driver assistance systems. A level five autonomous vehicle will have complete control over the driving task, requiring no human input. As a result, a level five car is projected to have more than thirty additional sensors of a much wider variety to cover the immense number of tasks an autonomous vehicle will need to perform. On top of the ultrasonic, surround camera, and long- and short-range radar sensors of a level two car, level five will require long range and stereo cameras, LiDAR, and dead reckoning sensors.

Lower-level automation requires fewer sensors, fewer network connections, and thus generates less data. Level 1 vehicles (think current driver assistance systems) require about 8 sensors, while a fully autonomous vehicle is expected to carry at least 32. Each of these sensor types generates data at different rates. In a recent presentation, Stephan Heinrich (2017) from Lucid Motors shared some estimates on the raw sensor data generated by each type of sensor, summarized in the table below:
| Radar | 0.1-15 Mbit/s/sensor |
| LIDAR | 20-100 Mbit/s/sensor |
| Camera | 500-3500 Mbit/s/sensor |
| Ultrasonic | <0.01 Mbit/s/sensor |
| Vehicle motion, GNSS, IMU | <0.1 Mbit/s/sensor |
Based on these numbers, Heinrich estimates that a vehicle at the lower end of the autonomous spectrum will produce about 3 Gbit/s of data, which amounts to about 1.4 terabytes every hour. At higher levels of autonomy, the total sensor bandwidth will be closer to 40 Gbit/s and approximately 19 terabytes per hour. According to the AAA American Driving Survey (2019), the average American spends 51 minutes driving every day. Over a whole year, that is 18,615 minutes, the equivalent of almost 13 full days. Thus, at the data rates above a vehicle could generate 434 TB for lower level autonomy or up to 5,894 TB of data for higher-level autonomy, in just one year!
Based on these estimates, a single autonomous car will produce more data in a year than the roughly 320 million monthly users of Twitter create (Kastrenakes, 2019; Matthews, 2018). Multiply this by millions of autonomous vehicles and you can get an idea of the crippling data crunch that will result from mainstream adoption of autonomous vehicles.
The Data Management Dilemma
With all this data, it becomes critical to find out how much of the data is useful and how much can be deleted. Autonomous vehicle manufacturers will need to make critical decisions regarding what data to keep, where it should be processed, and how much and for how long it should be stored. In addition, automotive manufacturers will need to determine how to leverage the data to deliver superior mobility experiences that are safer, personalized, convenient, and affordable.
Processing the terabytes of data from autonomous vehicles requires a huge amount of memory, powerful applications and processing power after transferring the data into the cloud. In some cases, however, the inherent latency of sending data to the cloud for processing, analysis, and receipt of instructions is unacceptable (figure 2). Autonomous vehicles cannot afford any latency for critical driving and safety functions. In an autonomous vehicle, a few milliseconds of delay can result in an accident and catastrophic loss of lives. Self-driving cars need to react in real time to changing road conditions; they can’t simply come to a stop while waiting for instructions or recommendations from a distant cloud server analyzing data.

Moving the processing power closer to the source of the data (the sensors on an autonomous car in this case) can dramatically reduce or eliminate latency in communicating and processing data. This is known as edge computing, where the process of analyzing data is executed near its source to reduce communication back to the central data center. In an AV, edge computing will be performed by the vehicle’s onboard computers and will be responsible for interpreting real-time sensor data to safely guide the vehicle through a driving environment. Edge computing will also determine what data needs to stay at the edge for immediate processing, and what data needs to be communicated to other parts of the network for deeper analysis.
Fog Computing: Demystifying Complex Driving Scenarios
While edge computing improves how autonomous cars sense, think and act in real-time, it is not enough for all driving conditions. As AVs share the roads with multiple human drivers, pedestrians, and cyclists under varying road and weather conditions, they will routinely need to identify safe solutions to significantly complex challenges. The onboard computers may provide quick responses, but they will need help from more sophisticated systems to choose an optimal course of action in these difficult situations.
A fog computing network may provide the answer by enabling processing with machine learning and AI algorithms on a local area network (LAN). A fog network provides a balance between the power of cloud computing with AI and machine learning, and the immediacy of computation at the edge. A fog network can also gather data from multiple vehicles, smart infrastructure, and other connected devices, providing each vehicle with a clearer picture of the overall driving environment.
Fog computing creates low-latency network connections between autonomous vehicles and processing hardware that is more powerful than what an AV could carry onboard. This enables the network to support more data and more sophisticated algorithms so AVs can make better decisions. This fog architecture also requires less bandwidth compared to transmitting data to a data center or cloud for processing. It can also be used in scenarios where a data center or cloud cannot be accessed, meaning data must be processed close to where it is created.
Fog network owners, such as automotive manufacturers, can also place security features in a fog network. From segmented network traffic to virtual firewalls, fog networks provide greater abilities to protect critical data and to keep AVs secure. Fundamentally, the development of fog computing frameworks gives automotive OEMs more choices for processing data wherever it is most appropriate to do so.
Some of the data produced by an AV as it operates will need to be stored for use at another time. In some cases, companies will only store data for a certain amount of time, while others will demand that data be stored in perpetuity. For example, the automaker will wish to keep some operational data to use in legal proceedings in case the technology fails in the field. All of this data has to be stored cost effectively, scaled, and available for analysis. Whether stored in a data center or on a commercial cloud service, the data must be secure and immediately accessible. Many major automotive companies are well aware of the importance of AV data management. For instance, Hyundai generates about 10 GB of data every second from its AV prototypes, but it only stores a portion of this data (Amend, 2018). Some is stored on the vehicle and off-loaded later to a server, and some is uploaded to the cloud (Amend, 2018).
Vehicle to X Communications
While AVs are the main subject of discussion regarding the evolution of how we get from point A to point B, other technologies may prove even more vital. Vehicular communications technologies, known broadly as vehicle-to-everything (V2X) communication, will form the foundation of future mobility systems. V2X technologies, such as vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I), enable real-time communication between vehicles, and between vehicles and their surroundings to provide a safe, convenient, connected, and affordable mobility experience (figure 3). Critically, these real-time communications allow vehicles to interact with each other and with the environment directly, in a way that humans cannot replicate. Such interaction can improve road safety, avoid traffic congestion, and reduce fuel consumption to enhance the overall mobility experience.
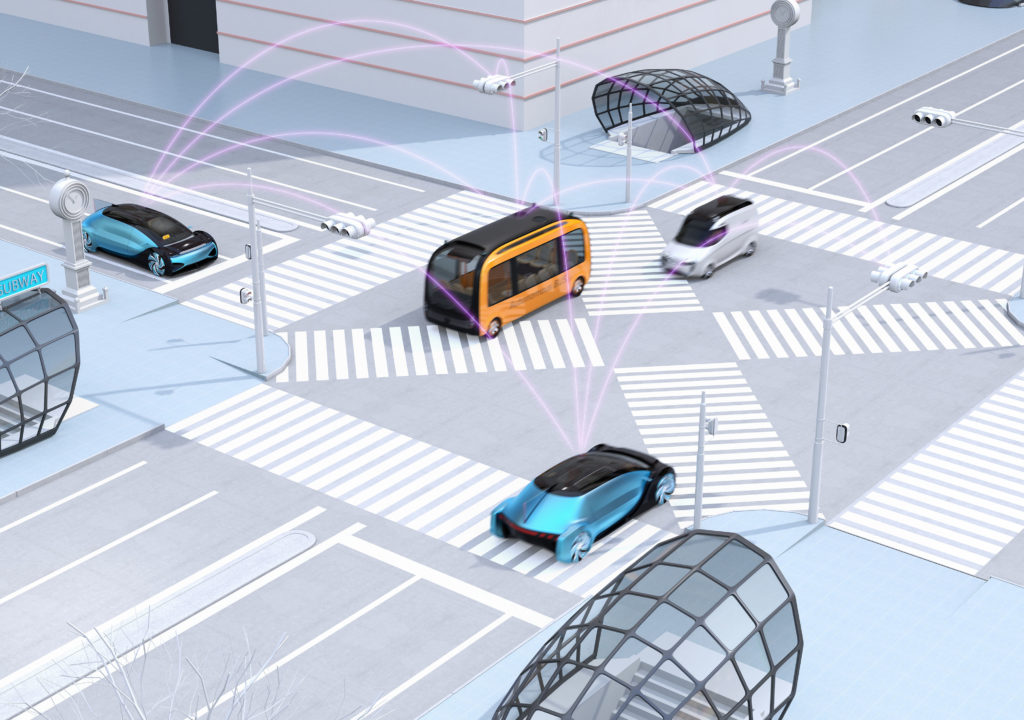
Here is a use case: an autonomous vehicle recognizes a fallen tree in the road and applies the brakes to avoid a collision. The vehicle can simultaneously warn vehicles behind it to decelerate, ensuring all vehicles safely come to a stop. The leading vehicle can even inform the local network of vehicles about the tree, allowing them to avoid that specific road until it can be cleared. To make this vision a reality, automotive manufacturers and suppliers are working together to develop vehicular communications based on cellular networks. The technology can use both today’s mobile network and future 5G networks, enabling transmission times in the millisecond range.
A V2X infrastructure is necessary to realize level 4 and 5 autonomous mobility. This infrastructure can integrate with fog computing centers to facilitate real-time data analysis, storage, and broadcast between many autonomous vehicles. As vehicles generate more and more data, properly managing and communicating that data will be crucial to successful operation.
Automotive embedded software will be responsible for managing and extracting intelligence from this data. The sophistication of this software will need to rapidly increase to cope with the explosion of data that the connected, autonomous car will generate. Part 3 will take a deeper dive into the growing importance of automotive embedded software.
About the Author
Piyush Karkare is the Director of Global Automotive Industry Solutions at Siemens Digital Industries Software. Over a 25 year career, Piyush has a proven history of improving product development & engineering processes in the electrical and in-vehicle software domains. His specialties include integrating processes, methods, and tools as well as mentoring product development teams, determining product strategy, and facilitating innovation.
References
Amend, J. M. (2018, January 18). Storage almost full: Driverless cars create data crunch. Wards Auto. Retrieved from https://www.wardsauto.com/technology/storage-almost-full-driverless-cars-create-data-crunch
Heinrich, S. (2017). Flash memory in the emerging age of autonomy [PDF document]. Retrieved from https://www.flashmemorysummit.com/English/Collaterals/Proceedings/2017/Proceedings_Chrono_2017.html
Kastrenakes, J. (2019, February 7). Twitter keeps losing monthly users, so it’s going to stop sharing how many. The Verge. Retrieved from https://www.theverge.com/2019/2/7/18213567/twitter-to-stop-sharing-mau-as-users-decline-q4-2018-earnings
Kim, W., Añorve, V. & Tefft, B.C. (2019). American Driving Survey, 2014 – 2017. AAA Foundation for Traffic Safety. Retrieved from https://aaafoundation.org/american-driving-survey-2014-2017/
Matthews, K. (2018, July 24). Here’s how much big data companies make on the internet. Big Data Showcase. Retrieved from https://bigdatashowcase.com/how-much-big-data-companies-make-on-internet/