Multi-target, multi-source fusion in autonomous driving – an introduction
In my last blogs, I considered some of the concepts for deploying machine learning within autonomous driving applications. In the next few blogs, I will explore some of the challenges and solutions when it comes to realizing effective sensor fusion for autonomous vehicles. This post introduces the topic and describes some of what’s motivating the work in this technical domain.
The intelligent agent framework of sense, understand and act outlines the three main requirements for highly assisted and autonomous driving. However, almost any conference featuring self-driving or driverless vehicles inevitably includes a discussion on the taxonomy of whether future vehicles should be described as self-driving or driverless — that is, whether they should be considered as autonomous or automated systems.
Many people focus specifically on the driver, or rather, the absence of the driver, and the level of intelligence that is necessary within the vehicle (as an intelligent agent) to replicate the actions of a human driver. But what if instead we focus on sensors and how the vehicle will use those sensors within the intelligent agent framework? Understanding the sensor system requirements allows us to research, develop and employ the most effective sensing methodologies for that particular driving task.
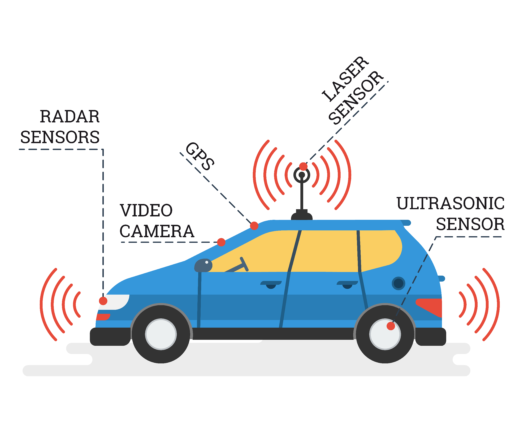
To start with, consider highly assisted driving (advanced driver assistance systems). In this context, sensors are used to measure a very specific aspect of the environment in order to plan a highly specific action without the need for understanding the whole picture. That is, a single driving task has been automated. An example of this would be a lane-keeping system, which generally uses computer vision to detect and locate visual lane markings. Using this sensed information, the system then infers vehicle position relative to those markings and updates the steering angle accordingly. The system is limited to this single task and requires very limited interaction with any other driving tasks.
Next comes automated driving (or highly-automated driving if you are designing some pithy marketing slides). In this context, the vehicle attempts to undertake a predefined set of instructions as precisely as possible. Thus, sensors are used to ensure that the vehicle closely follows these instructions, but still without a need to fully understand all the unknowns in the driving environment. An example of this is self-driving cars which drive a route thousands of times in order to build up a high-fidelity map of the environment and then during the automated phase, use the same sensors to precisely localize themselves within that map. The major limitation of these systems is that they need to be programmed how to behave for very specific situations, which requires substantial engineering input.
Finally, we have fully autonomous driving, the concept which has captured the imagination of researchers, engineers, the media and most importantly drivers themselves. In this context, the sensors are used to build up a full understanding of the environment such that the driverless vehicle can determine the most appropriate course of action in order to meet the driving task (i.e. drive to the desired location). Given that the driving scenario is dynamic, cluttered, obscured and often erratic, the sensing task is hugely challenging. This is further confounded by the point that automotive-grade sensors are somewhat crude, providing a coarse and discretely sampled representation of a complex analog world.
In this context, multi-sensor data fusion and machine learning are hugely important, providing the capability to detect, locate and identify both static and dynamic targets within the automotive environment. The challenge of detecting and locating (or tracking) multiple objects of interest, using multiple disparate sensors, can generally be broken down into the following steps:
- aligning the data from different sensors from both a spatial and temporal perspective
- associating the data recorded by disparate sources against the same object of interest
- mathematically fusing the different pieces of data/information
Fusing information in this way generally allows us to increase our information regarding an object of interest — such as reducing the uncertainty in location — and often through adding engineering knowledge into the system, allows us to infer states which are otherwise unobservable by single sensor modalities.
My next series of blogs will consider some of the fundamental challenges and techniques regarding data fusion from both an architectural and mathematical perspective.
Editor’s note: Daniel Clarke’s 2016 paper, “Minimum information loss fusion in distributed sensor networks,” prepared for the 19th International Conference on Information Fusion (FUSION), is available here.
Also, for more information, please see the Mentor whitepaper “Autonomous driving and the raw data sensor fusion advantage.”


