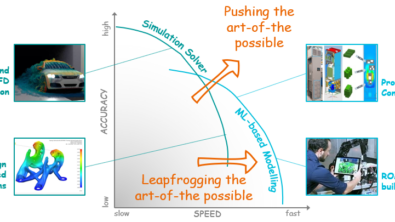
The potential impact of Large Language Models (LLMs) on Computer Aided Engineering

OpenAI’s ChatGPT has changed everything. From a rapid global awareness of the capabilities of freely available AIs to an appreciation of the utility that such Large Language Models (LLMs) can provide. The impacts are being felt in all fields, across all industries, homes and businesses. Computer Aided Engineering (CAE) is no exception, and if anything, that domain might benefit the most.
Humans are Lazy
As a species we have a proven track record of making life easier for ourselves. Why just speak when you could also write? Why write when instead you could print? Why read an entire book to find something out when you could just ask an LLM?
Maybe ‘lazy’ is the wrong word. Physics abounds with lowest energy state systems, and we’re no different. Humanity’s automation roadmap has been ongoing since we knapped the first flint and is showing no signs of letting up anytime soon. The furore surrounding ChatGPT and the supposed forthcoming AI apocalypse could be blamed on either our egocentrism or our tendency towards presentism. Either way, it’s not a revolution, it’s part of our evolution that’s been going on for at least 2.6 million years [1].
LLMs, an Albeit Big Step In Our Automation Roadmap
Maybe ‘Conversational AI’ is a better term. The ability to interact, with what is essentially just a software, using your own natural native language. For too long software has demanded from you the ability to speak its language, to know which buttons to press, which menu entries to find, to be able to translate your intention into a form that then enables the software application to provide you with the desired output. Being able to interact with a source of knowledge by just speaking (or typing) is about as lazy easy as it gets.
What Are LLMs?
LLMs are a class of AI models that are developed to understand human languages and generate meaningful text as an output.
History
LLMs are a relatively young technology though the idea to learn human (i.e. natural) languages by a computer is old. Conceptualizations began in the second half of the 20th century, but it took a long time to mature because of insufficient computing power. Developments were required on two fronts:
(1) The numerical representation of words, in order to make them processable by a computer
(2) Algorithms that can learn from and predict sequences or words/word fragments.
Early attempts used Markov-Chains, which have been replaced by recurrent neural networks with Long Short-Term Memory kernels. But it was the development and application of attention-mechanisms [2], that led to the most recent breakthroughs. The architecture is referred to as “transformers” (see picture below, [2]). The Multi-Headed attention is what makes the difference, and which captures long-ranged connectivity within text.
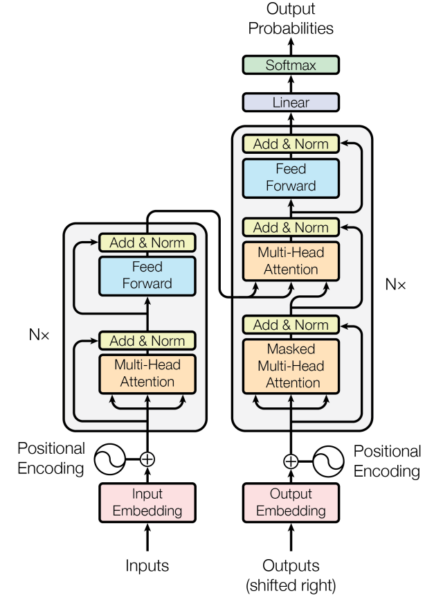
The developed models have become more powerful but are extremely data hungry and massive in terms of the number of network model parameters. Training such models requires huge demand of compute power (training of GPT4 costed upwards of 100 Million dollars), as well as a complex multi-stage training procedure involving self-supervised pre-training, reinforcement learning and finally fine-tuning through human-labelling.
LLMs Today
LLMs have seen significant advancements over recent years, with several key players driving forward the field’s development. Generative AI is a hot topic, with major companies and startups alike striving to push the boundaries of what these models can achieve.
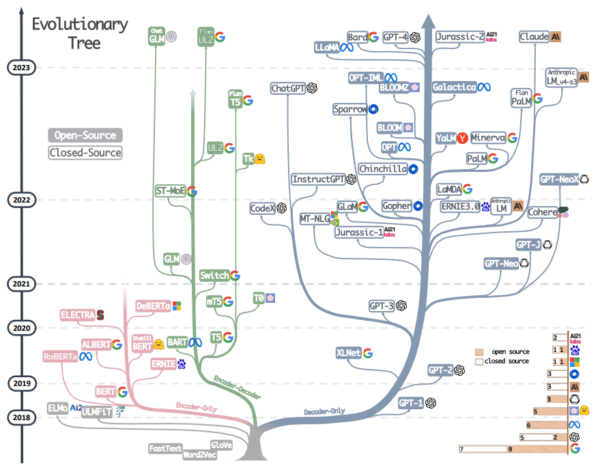
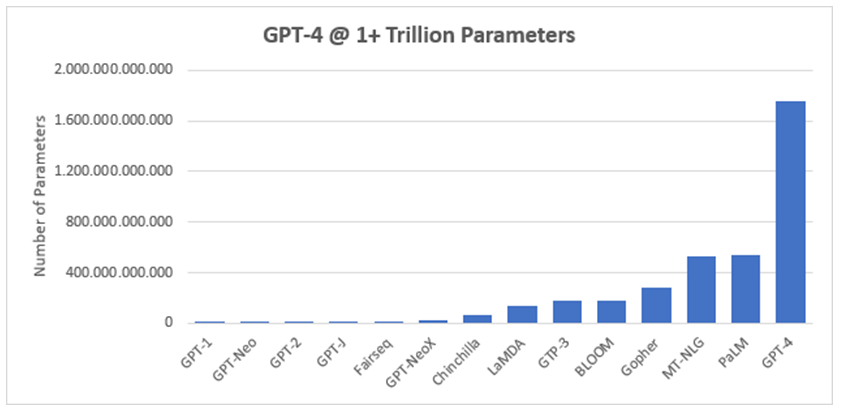
The Meteoric Rise of ChatGPT and Graphics
Since at least the release of GPT-2 in 2019, it was clear that generative language models were poised to unleash vast economic and societal transformation. Technologies like ChatGPT and Stable Diffusion didn’t come out of nowhere; they are the result of years of focused development and represent just the beginning of what’s to come in this AI space. The turning point though can be correlated to the number of LLM parameters and the resulting efficacy of the model.
The Future of AI: Models that Can Self-Improve
A promising avenue of research is enabling LLMs to generate their own training data, effectively bootstrapping their own intelligence. Google researchers have already made progress in this direction, creating an LLM that can generate detailed answers to its own questions and then fine-tune itself on these answers. This has resulted in new state-of-the-art performance on various language tasks [4].
The possibility of LLMs generating their own training data is particularly significant given the potential shortage of text training data. With estimates of the world’s total stock of usable text data ranging from 3.2 to 17.2 trillion tokens, we may soon exhaust the world’s supply of useful language training data. However, if LLMs can generate their own training data, this could lead to a significant leap forward in LLM development.
AI, ML and LLMs at Siemens
Siemens Digital Industries has embraced the opportunities that AI and its associated capabilities enable. Here are just a few examples of recent milestones:
- Siemens and Microsoft drive industrial productivity with generative artificial intelligence – 2023
- Siemens adds intelligence-based design to Xcelerator portfolio with latest release of NX – 2022
- Siemens delivers industry’s first Artificial Intelligence-powered CAD sketching technology – 2020
- Siemens updates NX Software with Artificial Intelligence and Machine Learning to increase productivity – 2019
What Opportunities Do LLMs Enable for CAE?
Computation Aided Engineering (CAE) entails the use of software algorithms and solvers to simulate the physical behaviour of products or processes. Be it CFD, FEA, Systems Simulation etc., and despite massive advances in capability and usability over the last few decades, these tools are still complex to use to the extent where training is required, and reference manuals are obligatory.
So how can LLMs make the use of CAE tools simpler, more accessible, more widely adopted? There exists a spectrum of opportunities. From the simplest inquiry regarding appropriate tool selection for a given application all the way through to a completely automated generative design capability that takes product requirements as input and directly generates a compliant design specification as output. Here a classification of LLM CAE opportunities:

Are all of these opportunities realised and commercially available today? Not yet. Although it’s possible to obtain quite generic information about various CAE tools from e.g. ChatGPT, the answers are often erroneous, incomplete or inconclusive.
Here though is one prototype example of how an LLM might better enable model creation, taking natural language as an input and using that to create a ready-to-solve Simcenter Amesim model:
A Dearth of CAE Specific Training Data
The usefulness of an LLM is constrained by the amount, specificity and quality of data used to train it. Commercially available LLMs today have been trained on a very broad range of information from sources such as Common Crawl and OpenAI’s own WebText, corpora of information gleaned from the internet over the last ~20 years. Broad but not deep, especially when it comes to more exotic and specialised areas such as CAE.
Realising any of the above CAE LLM opportunity use-cases is predicated on the availability of sufficient training data. Often considered commercial IP, commonly residing in the heads of experienced users or in PLM SDM archives, and often in a form that cannot be readily used to train. The bottlenecks to realisation are in the training data requirements more than in the inherent capabilities of an LLM to learn.
Knowledge Data Itself is Power
To unlock the potential of LLMs for CAE applications, training data will become the most valuable of commodities. Be it on-premise archiving of CAE user interactions, metadata annotating of simulation results for quality/robustness/accuracy, sensor measurements over the life-time of a product or even marketplaces where such data might be made available at a price. Any engineer who has worked with CAE tools over the years will likely have created GBs worth of data that is waiting to be valorized. So, next time you accept the terms and conditions of a dubious cloud-based offering, it’s advisable to be a little circumspect as to why and how your data will be used.
A Cause for Concern?
In the immortal words of Douglas Adams:
Is today’s scaremongering about the apocalyptic impact of the development of LLMs and AIs more generally being whipped up by those who would rather retain all that IP for themselves? Maybe that’s a bit too conspiratorial. Are there genuine fears surrounding job redundancy? Possibly, to the same extent that led to the Luddite rebellion in England in the 1810s, inspired by Ned Ludd’s (possibly apocryphal) destruction of two knitting frames in Leicester in 1779.
Automation has played a pivotal role in the evolution of humanity. For good or bad, we’re really quite effective at it. Would legislating against it reduce the risk of a global catastrophe? Would investing in it enable us to better care for our (only) planet and all the life that lives on it? Yes on both counts. Either way, LLMs are but just another (albeit big) step along our automation roadmap. Our ability to manage the consequences is what ultimately makes us human.
[1] Renfrew, Colin, and Paul Bahn (2015) Archaeology Essentials. 3rd edition. Thames & Hudson, New York.
[2] Vaswani et al. (2017), Attention is All you Need, NIPS
[3] Yang et al. (2023) Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond. https://arxiv.org/abs/2304.13712v2
[4] The Next Generation Of Large Language Models. https://www.forbes.com/sites/robtoews/2023/02/07/the-next-generation-of-large-language-models/