Detection and mitigation of AI bias in industrial applications – Part 2: Key points and justifications

In my first blog about the detection and mitigation of AI bias, we covered the concept of trustworthy Artificial Intelligence (AI) and its relationship to “desirable” and “undesirable” biases. In this second blog of my three-part series, we focus on the key aspects of AI bias for Industrial Applications. To my knowledge, almost all research in this area has so far focused on human-targeted bias (i.e., the so-called “social bias”) as opposed to bias that affects manufacturing decisions (i.e., what I call “industrial bias”). Although I will touch on the former, this blog is mainly concerned with the latter.
Key area of bias for industrial applications
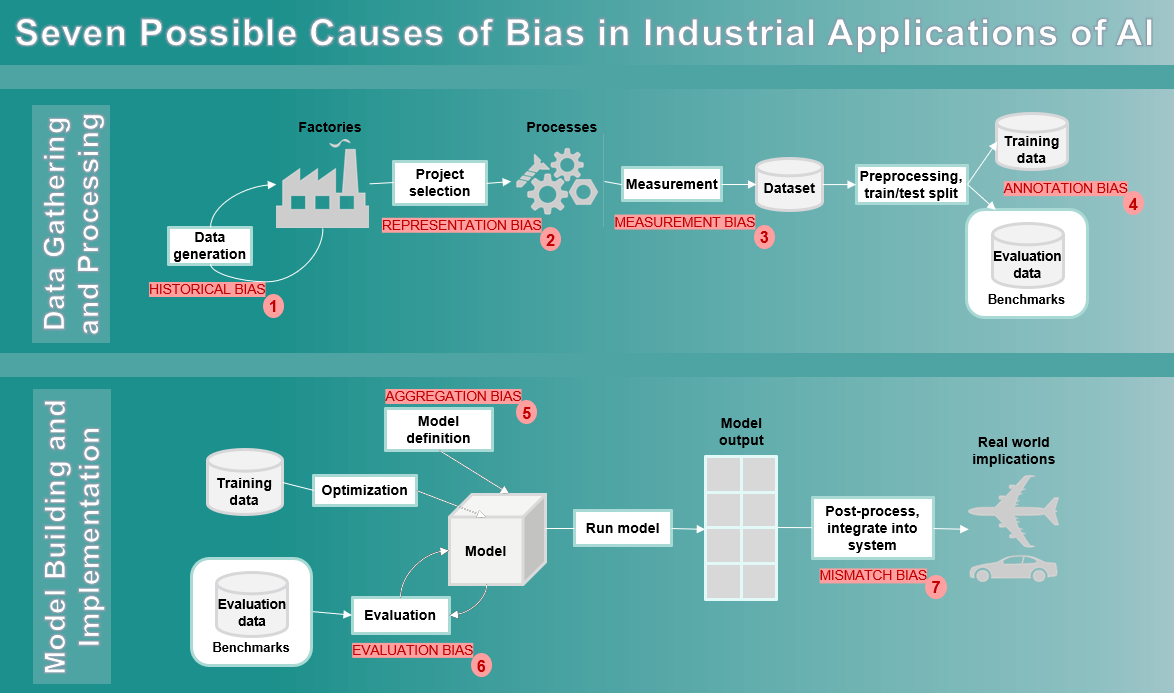
With so many sources of bias in the industrial application of AI, or more specifically Machine Learning (ML), it is not realistic to expect that we can eliminate all of them from every model we create. Instead, we need some practical steps that developers and implementors can and should take to mitigate the effects of bias as much as possible. The development of any ML-based solution should be accompanied by human-based testing, rigorous reviews, and consultation so that any remaining bias can be detected and mitigated in a timely manner. In other words, ML-based solutions in operation should enable human oversight ensuring that users of the system are informed about potential biases. This expectation, in turn, requires that our models can explain themselves and are transparent in how they make decisions [1-4]. By making our AI models more explainable and transparent, we can be more effective in minimizing bias. At Siemens, we strive for well-developed guidance and governance processes that can assist our developers incorporate mitigation strategies that reduce bias without interrupting progress. In this regard, the AI lifecycle for industrial applications shown in the figure above depicts seven possible sources of bias requiring explanation and scrutiny.
When collecting data, we need to first find a target subset that is relevant to our use case and then identify the features that must be measured and labeled. This target subset of data is subsequently divided into training data, test data, and validation data. (As you will see later, validation data requires special attention to ensure it covers all the bases.) With this background, the seven sources of bias in the industrial AI lifecycle in the two phases of “Data-Gathering and Processing” and “Model-Building and Implementation” are explained as follows:
- In the data gathering step, we should not rely solely on historical data because it represents the world as it is, and we may not always want that! In certain use cases, we may want to understand the cause and effect for something that has happened in the past; in this case, Historical bias is fine. However, in other cases, we may want to create a different future direction for a product and/or process; in such cases, we should use synthetic data to simulate the improvement and add this to the historic data.
- To address Representation bias, we must pay attention to underrepresentation or overrepresentation when defining and sampling from a vast amount of information. As indicated in Part I, we should sample at different times of the year, using data from different shifts of experienced and inexperienced operators under different conditions for manufacturing use cases; otherwise, the model created fails to generalize properly.
- Measurement bias happens when focus or proxy is misplaced, or data collection is distorted. For instance, if a specific group of shop-floor workers are more frequently monitored, more errors will be observed in that group, causing a harmful feedback loop. This kind of bias also happens if the method of measurement varies across groups.
- Annotation or labeling bias shows up if the labels created by humans are unconsciously biased in some way. The inherent bias that lives within us could easily find its way into how we annotate the training data. This “individual” bias is not necessarily a negative; it just means that we must have diversity among the individuals doing the labeling because people from various cultures could assign or interpret labels differently. For example, the meaning of the word “truck” might mean different things between India and USA and thus labeling might differ (also see Mismatch bias below).
- Aggregation bias means that a single AI model is unlikely to be well-suited to all situations for even a specific use case. A given variable/norm for a group in one setting can mean something quite different for a feature in another setting. Ignoring group-specific context and assuming one-size-fits-all will lead to a poor model in most cases.
- Evaluation bias is the most critical and the most problematic if it is not addressed. Humans must correctly anticipate what the system needs to deliver by having insights about the target use case in order to cover all possible variations. Perhaps creating a second layer of AI that monitors the first is the best practical strategy to get humans and their conscious and unconscious biases out of the way during the evaluation phase.
- Finally, a Mismatch bias happens when the created model is implemented in the wrong use case or is being used in the wrong environment/region. A recommender system designed for automotive harness cannot be used for aerospace harness because they have inherent differences; or a model intended for use in India cannot readily be used in USA unless it is generalized by correct labeling and is aware of where it is being applied.
At the Implementation phase, rigorous evaluation must be done through multiple iterations of use cases against benchmarks and validation data by independent engineers. If something goes wrong, every step of the process needs to be re-examined. That is why the suggestions made in Part 3 of this blog must be adhered to from the beginning to avoid such an outcome.
In our third and final blog of this series, we will explore several mitigation strategies for addressing harmful AI bias, provide several real-world industrial use cases, and conclude with a few recommendations.
Software solutions
Siemens Digital Industries Software is driving transformation to enable a digital enterprise where engineering, manufacturing and electronics design meet tomorrow. Xcelerator, the comprehensive and integrated portfolio of software and services from Siemens Digital Industries Software, helps companies of all sizes create and leverage a comprehensive digital twin that provides organizations with new insights, opportunities and levels of automation to drive innovation.
For more information on Siemens Digital Industries Software products and services, visit siemens.com/software or follow us on LinkedIn, Twitter, Facebook and Instagram.
Siemens Digital Industries Software – Where today meets tomorrow.
References and related links
- Harvard Business Review: We need AI That is Explainable, Auditable, and Transparent, October 2019.
- Mohsen Rezayat: Adoption, Value, and Ethics of AI in Software, August 2021.
- NIST special publication 1270: A Proposal for Identifying and Managing Bias in Artificial Intelligence, June 2021.
- Harini Suresh and John Guttag: A Framework for Understanding Sources of Harm Throughout the Machine Learning Life Cycle, December 2021.
About the author: Mohsen Rezayat is the Chief Solutions Architect at SIEMENS Digital Industries Software (SDIS) and an Adjunct Full Professor at the University of Cincinnati. Dr. Rezayat has 37 years of industrial experience at Siemens, with over 80 technical publications and a large number of patents. His current research interests include “trusted” digital companions, impact of AI and wearable AR/VR devices on productivity, solutions for sustainable growth in developing countries, and global green engineering


