AI Foundations: How does neural network training work?

Understanding the building blocks of artificial intelligence.
Consider a scene in a park with a mother and her young child. The mother points to a duck on the lawn and says, “Duck.” Her child repeats back, “Duck.” The mother then points to a dog nearby and says, “Dog.” The child replies, “Dog!” A few minutes later, mom points to some ducks by the path and asks, “What are those?” The child replies, “Dog!” Mom gently corrects the child as they move down the path. Around the corner there is a group of ducks on the pond and the mother asks, “What are those?” The child yells out, “Duck!” It has taken a few tries over the course of minutes, but the child recognizes a duck at this point. Ducks are similar in appearance, but dogs come in many shapes and sizes, so it will take a while for the child to correctly identify them. This scene is a human version of supervised learning.
Supervised learning
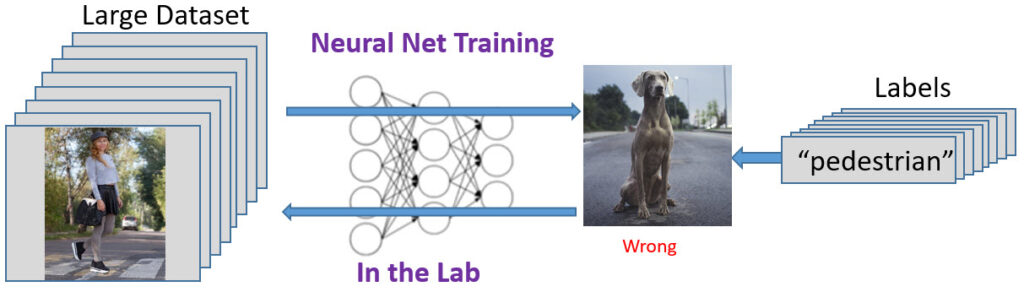
Design teams use big data sets to train a neural network to find patterns in order to identify a particular object or situation, or to uncover a data point that otherwise is not obvious to humans. In order to train the neural network, as much data as possible is desired. Instead of a mother providing her voice to identify objects, for AI supervised learning, each data element needs to be labeled by humans and sometimes the data needs to be cleaned. For example, an image database attaches a label to identify the image and sometimes each image needs to be scaled so that they are all the same size. This takes time and can be expensive. That is why there are many open source communities for clean databases to train neural networks.
However, there is some concern in the AI community about so many training projects using the same databases. There could be issues such as outlier “holes” in the data than only become apparent when the system is in its working environment. There is also concern about bias, which is when the network consistently learns the wrong concept due to over-simplified labels. The way labels are assigned by humans can be biased as to their point of view.
The neural network learns based on the labeled data. This learning takes place within a lab using large computer networks. Currently, software vendors are experimenting with generating labeled data automatically. For example, there are tools to generate pictures of people’s faces for facial recognition training. Or, tools that generate synthetic objects that simulate driving conditions.
Supervised learning typically employs techniques that divide the dataset into groups based on the labels or methods that find continuous patterns in the labeled data (regression). Between these two techniques there are many algorithms that designers can choose from with fancy names like Naïve Bayes Classifiers and K-Nearest Neighbor to divide the data and Linear Regression and Decision Trees for finding regressions.
Unsupervised learning
Partly because of the huge cost of databases for supervised learning and partly because researchers know that humans learn unsupervised, AI experts figured out how to perform unsupervised learning in order to train neural networks. Unsupervised learning does not depend on labeled data and the neural network performs learning from the data automatically. Object recognition systems often employ frontend code to automatically scale images or apply certain filters to cut down elements of the images for easier and quicker analysis, avoiding human interaction.
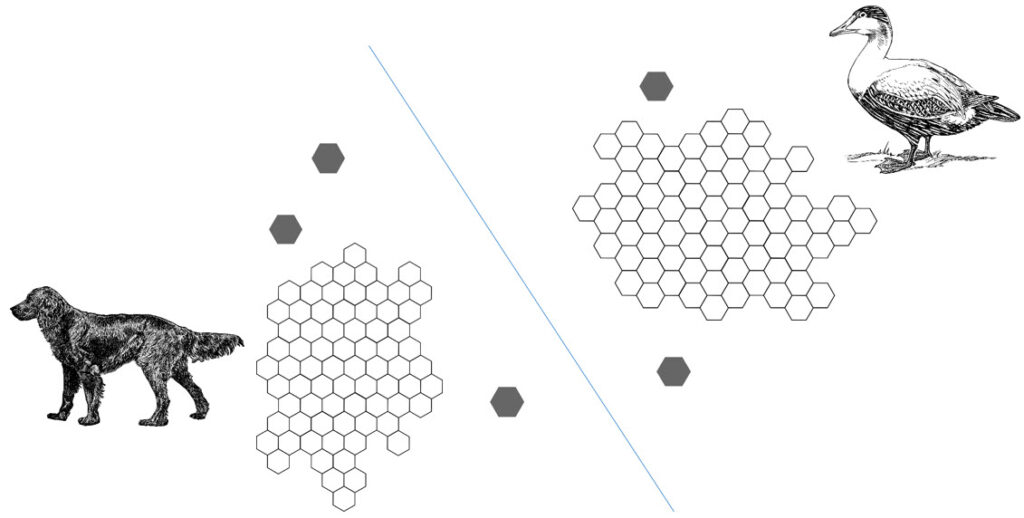
Teams employ different algorithms for unsupervised learning to see which one does the best job for the task at hand. They also try different algorithms to determine which comes up with the correct answer the fastest. A common algorithm type is Clustering, where similar unlabeled data is placed in together in groups to classify the data (Figure 10). The algorithm takes a guess as to what the item is and then iterates using calculations to get a positive result. How it decides what items are similar for each group is performed in several ways. Typically, the algorithm performs a calculation to determine distances or angles between two data points within a graph. Other approaches look for outlier data points in order to try to find unexpected relationships, or they implement a reward or penalty for reinforcement learning.
The smart folks in the world of AI also figured out that they could use a blend of supervised and unsupervised data to solve a problem. In this multi-level system, the neural network learns using a set of labeled data and then assigns labels to data that has no labels. This technique is useful for detecting unexpected data patterns using expected (labeled) data.
Is unsupervised learning better than supervised learning? It turns out that both learning types are employed in AI systems today, depending on the application. An AI system is focused on doing one application well. For example, excellent systems exist today that employ supervised learning, such as speech and object recognition, email spam detection, and biometric analysis (retina, fingerprint, and voice). Unsupervised learning is employed in systems that detect anomalies, recognize patterns, predict trends, and to make recommendations (like music and movies). The choice of learning techniques typically comes down to weighing the advantages and disadvantages of each. What algorithms to employ within the chosen learning technique is mainly a trial and error process. Luckily, there are many algorithms out there that are freely available to use as building blocks, so teams do not have to invent them from scratch. And, each of the algorithms have parameters or “knobs” that can be adjusted to improve results.
A big question in the AI world today is how neural networks employed in systems are actually learning in order to test, debug, and tune the results. This field of research is called self-explaining neural networks. Next up, how do neural networks learn?


