Retrieval-Augmented Generation (RAG) and LLMs for smart code generation: Advancing Plant Simulation SimTalk and beyond
Applying RAG and LLMs for Smart Code Generation in Siemens Plant Simulation

Senior Data Scientist
Siemens Digital Industries Software
As a Senior Data Scientist at Siemens Digital Industries Software, my work is dedicated to Artificial Intelligence – Machine Learning (AI-ML) advancements on the Innovation, Strategy & Research team in the Digital Manufacturing business unit. Recently, I wrote about how we are applying artificial intelligence (AI) at Siemens to help our users gain major efficiencies and become more productive.
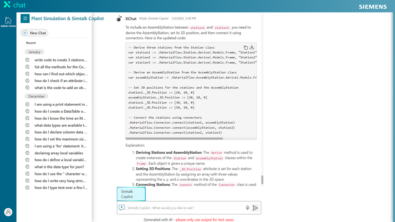
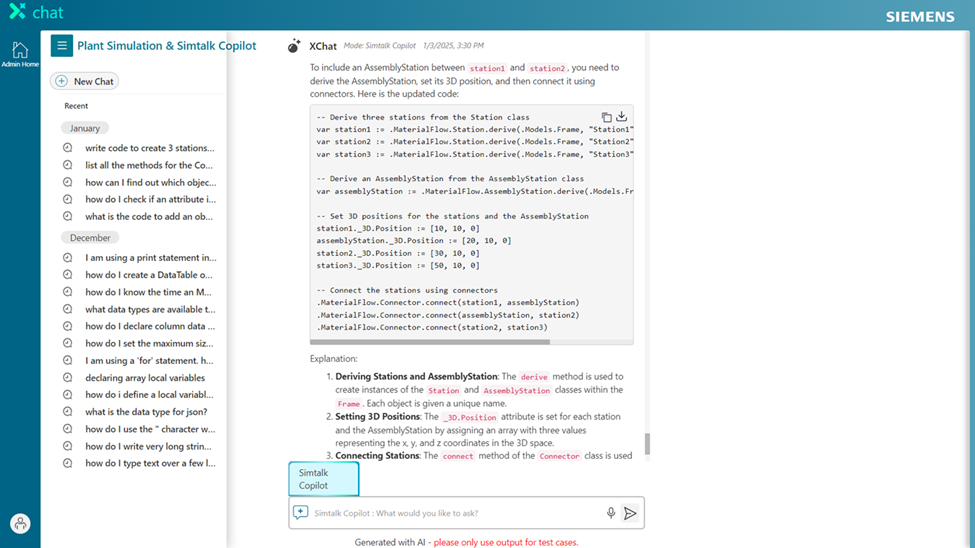
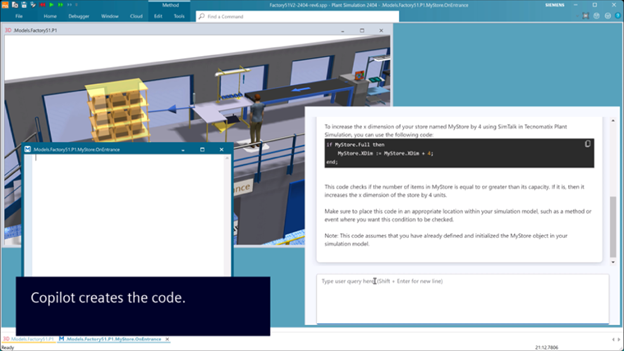
The series of blogs linked in this article dive into the technical details of our experience of building a code generation assistant for SimTalk, the scripting language used in Siemens Plant Simulation software. This powerful tool enables our users to model, simulate, and optimize manufacturing systems and processes. By leveraging SimTalk, users can customize and extend standard simulation objects, making it possible to create more realistic and complex system models.
Exploring the potential of Large Language Models
This project unlocks the potential of Large Language Models (LLMs) for generating SimTalk code, the scripting language in Siemens Plant Simulation software. SimTalk empowers users to customize and extend simulations, driving greater efficiency in manufacturing optimization.
Although SimTalk has limited publicly available training data, we’ve found that with well-structured prompts augmented with relevant code examples, function details, and expected behavior — LLMs can generate highly useful code. This breakthrough significantly boosts productivity and aligns with our mission to enhance user experience.
Plant Simulation SimTalk use case
Our extensive SimTalk documentation serves as a powerful foundation for contextual code generation. In this series, we’ll explore key Retrieval-Augmented Generation (RAG) strategies that make intelligent code generation more accessible and effective. RAG is a technique that enhances generative AI models by incorporating information retrieved from external sources, like databases or knowledge bases, to improve the accuracy and context of generated text.
Evaluating Embedding Models for Domain-Specific Retrieval
In my first blog, I discuss how to choose the best embedding model for Retrieval-Augmented Generation (RAG) pipeline. As a reminder, Retrieval-Augmented Generation (RAG) is a powerful technique that significantly enhances the performance of large language models (LLMs) by dynamically integrating external knowledge sources into the generation process. This integration allows models to access up-to-date, domain-specific information that may not be captured in their pre-training, making them much more versatile and reasonably accurate in responding to complex queries.
Naturally, the success of RAG systems largely depends on quality of retrieval. Recently, embedding models became a critical component of any RAG application, as they enable semantic search, which involves understanding the meaning behind user queries to find the most relevant information. This involves selecting and/or fine-tuning embedding models that transform textual data into high dimensional numerical vectors. These vectors represent semantic meaning, enabling efficient and relevant retrieval of information that directly supports the generation tasks. Embedding models must be carefully chosen to fit the specific requirements of the domain, as the quality of retrieval directly impacts the quality of generated responses.
For example, in the manufacturing industry, using an embedding model pre-trained on or fine-tuned on industrial data can significantly improve retrieval quality, ensuring that the retrieved information is accurate and contextually relevant for the target user. By leveraging effective retrieval mechanisms, RAG systems can bridge the gap between static model knowledge and dynamic, context-specific information.
This approach ultimately leads to more informative and contextually aware outputs. In certain cases where off-the-shelf embedding models are not trained on the domain of your interest, it will not be able to capture the nuances of user query. This will in turn harm the retrieval performance, leading to poor answers or hallucinations by LLMs. One effective way to deal with this limitation is to fine-tune the embedding models to capture domain-specific nuances. This ensures that the retrieval process is precise, allowing RAG to provide highly relevant and semantically rich responses.
Selecting the Optimal Embedding Model
A key part of building a strong RAG pipeline is choosing an embedding model that fits the specific needs of your domain. Testing multiple models on your dataset is essential to find the one that works best. Metrics like precision, recall, and relevance are important for evaluating model performance. Precision measures how many of the retrieved results are relevant, recall measures how many of the relevant results are retrieved, and relevance assesses the overall usefulness of the retrieved content. For example, having both high precision and recall ensures that you get accurate and complete information, which is crucial for downstream tasks.

Fine-Tuning for Better Alignment
In my second blog, I discuss how pre-trained embedding models provide a good starting point, but fine-tuning them on your specific data can lead to significant improvements. Fine-tuning involves adjusting the model’s parameters to better capture the details of your domain, resulting in more accurate and relevant embeddings. By tailoring the model to the nuances of your data, fine-tuning ensures that embeddings are more aligned with domain-specific vocabulary, context, and intricacies, thereby improving downstream performance across various tasks.
For example, techniques like Matryoshka Representation Learning (MRL) can be especially helpful by making it more flexible. MRL allows the creation of embeddings at different levels of granularity without losing performance, making the process more computationally efficient and adaptable. This property ensures that the applications can use simpler embeddings for straightforward tasks while employing more detailed embeddings when needed, thereby optimizing the trade-off between computational load and performance.
Additionally, MRL helps in reducing redundancy within the embedding space, allowing for more compact representations that retain the necessary information. This flexibility makes MRL particularly effective for applications requiring multi-level representation, where different types of tasks need varying levels of detail in their embeddings.
Evaluating Retrieval and Generation Pipelines
To achieve the best results from a RAG system, it’s important to thoroughly evaluate both the retrieval and generation components. Creating a “golden dataset” — a set of sample queries paired with correct answers — allows for systematic testing of different configurations. For example, this dataset could include frequently asked questions with verified answers or common user queries and responses collected from customer support. The dataset should be diverse enough to cover different edge cases and typical scenarios, ensuring a thorough evaluation of the RAG pipeline. For example, an edge case might involve queries with ambiguous wording or uncommon terminology, which tests the system’s ability to handle less straightforward inputs. Additionally, using LLMs during the evaluation process can help streamline testing and provide valuable insights into the relevance and accuracy of both the retrieved information and generated responses.

By carefully selecting and fine-tuning embedding models and rigorously evaluating retrieval and generation pipelines, organizations can unlock the full potential of RAG systems. This approach not only improves the performance of AI applications but also ensures they align with specific business goals, driving innovation and efficiency in an AI-powered world.


![Reshaping the world with digital manufacturing [VIDEO]](https://blogs.sw.siemens.com/wp-content/uploads/sites/7/2024/07/Zvi_2024_2-395x222.png)