SemiWiki: What a Difference an Architecture Makes: Optimizing AI for IoT
Excerpt from article: “What a Difference an Architecture Makes: Optimizing AI for IoT”
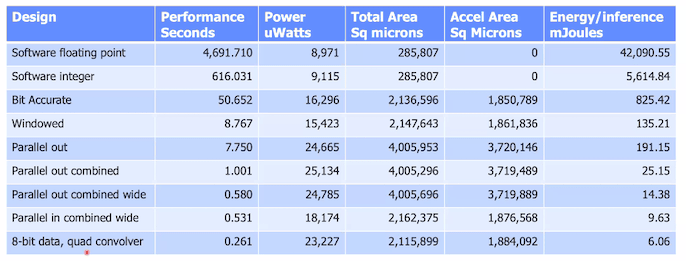
Last week Siemens EDA hosted a virtual event on designing an AI accelerator with HLS, integrating it together with an Arm Corstone SSE-200 platform and characterizing/optimizing for performance and power. Though in some ways a recap of earlier presentations, there were some added insights in this session, particularly in characterizing various architecture options.
Mike Fingeroff kicked off with high-level design for the accelerator, showing a progression from a naïve implementation of a 2d image convolution with supporting functions (eg pooling, RELU) in software. This delivered 14 seconds per inference where the final goal was 1 second. His first goal was to unroll loops and pipeline. New here (to me at least) is that Catapult generates a GANTT chart, giving a nice schedule view to guide optimization. So Mike unrolls and finds he has memory bottlenecks, also highlighted by a Silexica analysis. Not surprising since he’s using a 1-port memory, again with naïve reads and writes. He switches to a shift-register and line-buffer architecture supporting a 3×3 sliding window in convolution and the bottleneck problem is solved. He also looks at Silexica analyses to decide how/if to buffer weights. Now he’s down to just over a second per inference with bias, RELU and pooling still in software (running on the embedded CPU).
Read the entire article on SemiWiki originally published on May 28th, 2020.