Endianness
In almost all modern embedded systems, memory is organized into bytes. CPUs, however, process data as 8-, 16- or 32-bit words. As soon as this word size is larger than a byte, a decision needs to be made with regard to how the bytes in a word are stored in memory. There are two obvious options and a number of other variations. The property that describes this byte ordering is called “endianness” [or, sometimes, “endianity”].
Broadly speaking, the endianness in use is determined by the CPU. Because there are a number of options, it is unsurprising that different semiconductor vendors have chosen different endianness for their CPUs. The questions, from an embedded software engineers perspective are “Does endianness matter?” and “If so, how much?” …
First of all we need to provide some boundaries for this discussion. I am going to just consider 32-bit CPUs – the same issues apply to 16- and 64-bit devices. Even 8-bit devices typically have instructions that deal with larger data units. I am also going to limit my consideration to the obvious endianness options: least significant byte stored at lowest address [“little-endian”] and most significant byte stored at lowest address [“big-endian”]. These two options may visualized quite easily:
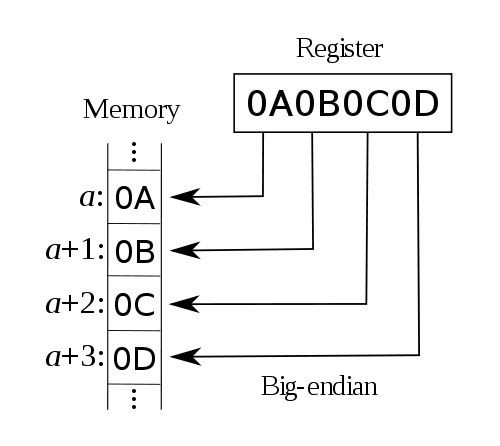
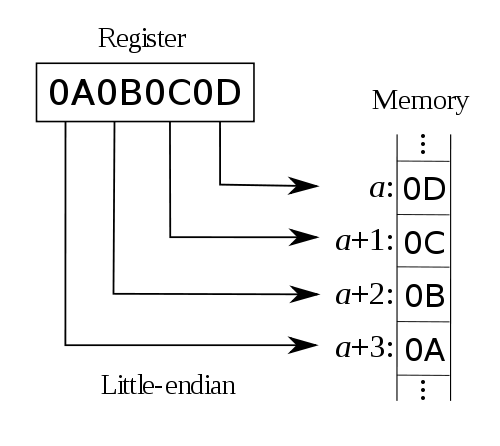
There are also other possibilities, like using little-endian within 16-bit words, but storing the 16-bit words inside 32-bit words using big-endian. This is commonly called “middle-endian” or “mixed-endian”, but rarely encountered nowadays. The order of bits within a byte is also potentially arbitrary, but I will ignore that too.
Examples of little-endian CPUs include Intel x86 and Altera Nios II. Big-endian CPUs include Freescale 68K and Coldfire and Xilinx Microblaze. Many modern architectures facilitate both modes and can be switched in software; such “bi-endian” devices include ARM, PowerPC and MIPS.
There are broadly two circumstances when a software developer needs to think about endianness:
- data transmitted over a communications link or network
- data handled in multiple representations in software
The former situation is quite straightforward – simply a matter of following or defining a protocol. The latter is more tricky and requires some thought.
Consider this code:
unsigned int n = 0x0a0b0c0d;
unsigned char c, d, *p;
c = (unsigned char) n;
p = (unsigned char *) &n;
d = *p;
What values would c and d contain at the end? Whatever the endianness, c should contain the value 0x0d. However, the value of d will depend on the endianness. On a little-endian system d will contain 0x0d; on big-endian it will have the value 0x0a. The same kind of effect would be observed if a union were to be made between n and, say, unsigned char a[4].
So, does this matter? With care, most code may be written to be independent of endianness and I would contend that almost all well-written code would be like this. However, if you do build in an endianness dependency, as usual, good documentation/commenting is obviously essential.
“However, the value of d will depend on the endianness.” why?
Dinesh: Because d is a pointer to char and it is pointing at a [32-bit] int. Which end of the int it is pointing to depends on the endianness.