How to sustain the ongoing evolution of industrial simulation?
The evolution of industrial simulation has been marked by a transition from primarily scientific and proprietary software to a market dominated by sophisticated commercial products. Foundational technologies underpinning Computer Aided Engineering (CAE) and simulation tools have concurrently undergone exponential development. Beyond just Moore’s Law and its impact on compute capabilities, significant progress on the algorithms themselves has resulted in a dual advancement of algorithms and hardware.
How though will industrial simulation manage to sustain its stellar rise? Can we simply continue to rely on compute hardware roadmaps in making simulation ever faster? What impact will AI and ML have? Will other non-functional aspects of CAE such as accessibility, usability, interoperability or security come to dominate future CAE roadmaps?
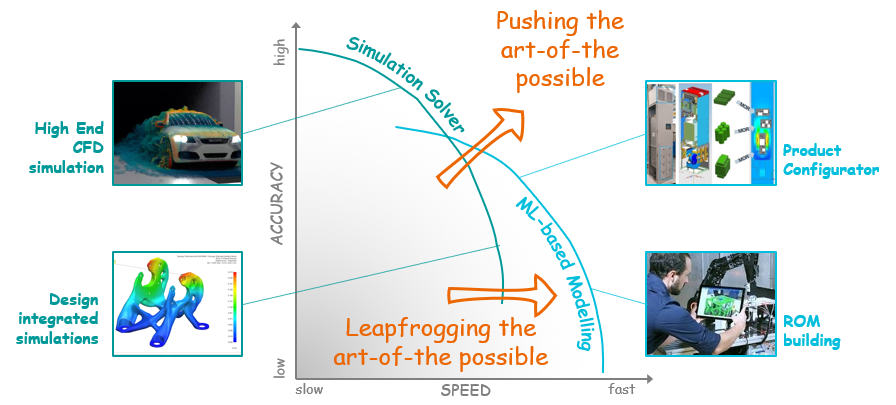
The art of the possible needs to be constantly challenged to continue to continue to push out the Pareto front of Accuracy vs. Speed.
In our previous blog On the ongoing evolution of industrial simulation we proposed 6 vectors along which CAE might evolve in the future. In this blog we look at the key technological drivers required to sustain the continued evolution of industrial simulation.
A symbiosis of hardware and algorithms is leading the way
If the engine is computer hardware, then computational algorithms are the fuel. To date simulations have become faster and more accurate thanks mainly due to compute hardware roadmaps. Putting a bigger engine in a car isn’t the only way to make it faster though. Numerical algorithms themselves have also evolved at similar rates[1]. Mathematics has played a pivotal role in this. While the previous generation of simulation tools required millions of computations to solve a linear system of equations with thousand degrees of freedoms, modern mathematics has allowed to reduce the required number of computations to a few thousands for a large class of problems. Check out our earlier blog on Speedy simulations: From Moore’s Law to more efficient algorithms where we look into this in more detail.
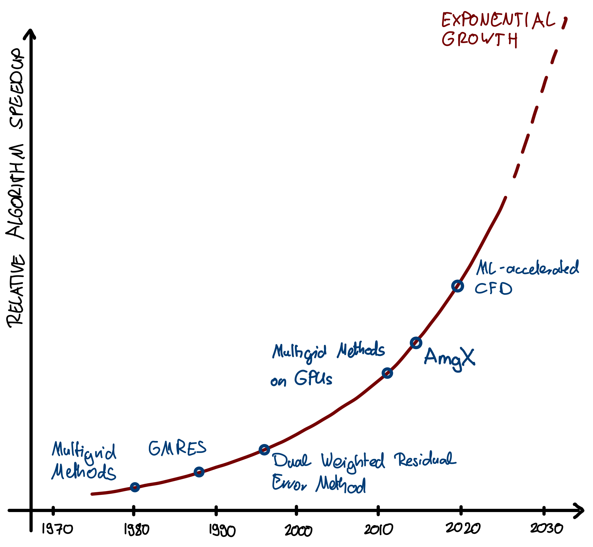
If anything, it is more likely that the next wave of disruption will come from novel algorithmic approaches rather than hardware (especially considering the promise of a quantum computing revolution is still some way off). For example stochastic computing concepts[2] or the combination of ML and classical solver technologies[3] promise orders of magnitude acceleration in solver speed – this at a fraction of the cost of implementation compared to evolving classical approaches to achieve the same.
Computing fabrics scale simulation opportunities
Until the 1980s, the realm of computing was a privilege reserved for a select few. The exorbitant costs associated with computing confined its utility to a narrow spectrum of carefully chosen use cases. However, the technological landscape has undergone a revolutionary shift in the past few decades. For example, the 2023 Apple MacBook Pro (M2 Max), boasting a staggering 13.6×1012 FLOPS, making it 272 million times more powerful than the 1979 IBM 5150 (Intel 8088 + Intel 8087 Co-processor) – the pioneering personal computer – which managed a modest 50×103 FLOPS.
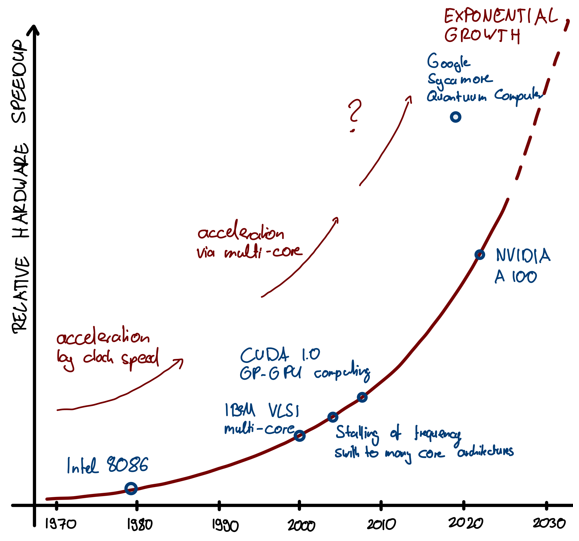
Even as Moore’s law in its original form is approaching its physical and economic limits, compute power is expected to grow continuously by leveraging other computational paradigms[4]. The recent NVIDIA GB200 NVL72 multi-node Blackwell system offers an impressive 1.4×10¹⁸ FLOPS performance (Exascale) within one rack specifically tailored for AI applications[5]. Although FLOPS as a metric can’t be directly applied to quantum computing, it is envisioned that quantum will far exceed the performance of classical architectures – see also our blog on Exploring the quantum frontiers of differential equations in engineering.
But it is not only the impressive increase in number crunching capabilities. Also accessibility to data and compute resources has immensely increased. The proliferation of the Industrial Internet of Things (IIoT), incorporating devices furnished with sensors, enormous computational processing capabilities, and other technologies, facilitates seamless data exchange and connectivity over the Internet or other communication networks. The availability of IoT devices will be followed by a massive increase in cloud and edge computing resources. Combined with an exponential evolution of communication technologies, we will see a convergence of edge and cloud computing towards a compute fabric. Thereby, individual assets will have access to massive, shared compute resources (locally and cloud) enabling them to perform computation tasks at any scale, anywhere, anytime.
Data-based and physics-based ML paradigms are converging
The convergence of data- and model-based ML paradigms is becoming increasingly evident and probably the biggest potential disruptor of simulation as we know it today. Both physics-based simulations and data-driven methods aim to predict or explain the behavior of complex systems. They share a common objective, albeit their foundational technical approaches differ. Physics-based modeling relies on established predictive physical equations, whereas data-driven methods capitalize on abundant previously measured data sources available today. In fact data-based methods are emerging as a fourth scientific and engineering paradigm[6] (complementing theory, experimentation, and computation).
Compared to other technologies, AI and ML are expected to have the biggest impact on product design and development over the next 5 years, backed up by 65% of simulation experts[8]. While they will not replace simulation technology, the symbiosis of the two will be heart of the disruption. Similar to the symbiosis of test and simulation, where in the past the increased adoption of simulation has actually led to the necessity of doing more tests. However, despite the promise of ML to massively accelerate simulation predictions (see also our blog Beyond traditional engineering simulations: How Machine Learning is pioneering change in engineering), the adoption of AI and ML in engineering is still low[9]. Challenges are the lack of human resource as well as the missing trust in AI-based simulations in the engineering domain.
The key challenge, when it comes to a stronger utilization of AI and ML based methods in engineering, is the lack of data in engineering as well as its size, e.g. the result of a single CFD simulation can be larger than datasets used to train coding co-pilots. While in the context of simulation, it is typically the algorithms making the difference, in the context of AI it is the access to data[10] and so the provision of data will become a ‘currency’ in economic value chains.
Usability and automation will be key differentiators
Historically, the focus of CAE simulation tools has been on their primary functional capability: the accurate simulation of physical phenomena. Comparatively, usability has never been the focus. With the ambition to broaden the user base of CAE tools, non-functional competitive advantage in terms of usability, automation and workflow integration will become more important in the future. Today, the majority of first-time users are overwhelmed by the complexity of the interfaces offered by simulation tools[11]. With only very few engineers being digital native as of today, and having grown up with complex interfaces (often command-line based), this paradigm has not really been challenged. However, this is a major limiting factor when it comes to adoption of simulation tools in other domains and by different classes of user persona.
Without increased usability, democratization and scalability of simulation will not be possible. For consumer products usage centric UX is a de-facto element in most buying decisions. With more and more digital native engineers, this will be also a key element considered by future users when deciding for CAE tools. In our blogs on Computer Aided Engineering in the Industrial Metaverse (Part 1 and Part 2) we are investigating one potential future path.
Interoperability is mandatory
Interoperability between tools has always been a key issue in Digital Engineering. Most companies obtain their computational design and engineering tools from different providers and in addition collaborate with suppliers who themselves often use different tools. So far, the corresponding challenges are addressed by a combination of manual bi-directional coupling between tools as well as an ever-increasing use and adoption of standards. The latter includes standards such as STEP[12] (for 3D models), the Functional Mock-Up interface[13] (for systems simulation models) or SysML v2[14] (the next generation systems modelling language). Next to the development of specific standards, it is also observed that more and more simulation vendors are providing APIs to their tools[15] and models[16].
Due to increased interoperability, exchanging individual simulation tools in specific engineering workflows will be made easier, whereas so far the high sunken costs with changing simulation tools have provided a natural moat for the vendor. But it is very unlikely that any future simulation tool provider can be successful without supporting and interacting within more open ecosystems, as touched on in our blog Simcenter meets Catena-X. Another great example being Omniverse which is not only offering novel collaboration opportunities in the computer graphics community but also has the ambition of supporting industrial applications[17].
Model exchange platforms form new engineering ecosystems
Engineering models – including simulation models – have always been proprietary, but the trend of interoperability, cross-company innovation, and ecosystem thinking are fostering an increase in information and data exchange across companies. In addition, companies have become more open to share their data, specifically motivated by the transformative power of AI and ML which relies on data generosity. Specifically, sustainability and circularity will require the sharing of data and models across companies as well as across the whole life-cycle, e.g. supporting tracking of sustainability KPIs, such as supported by Siemen’s Green Digital Twin[18], or easing recycling by closely tracking material properties / models. Already today software providers are moving towards a simulation-as-a-service business model, in the future we might see a shift to a model-as-a-service business.
Enabling the exchange of data and models between different companies and organizations also fosters innovative business models, smoother workflows, and the reuse of knowledge. This approach, already proving its worth in fields like game design[19] and computer-aided design[20], substantially enhances productivity by cutting down on the manual effort needed for creating high-quality models.
However, model sharing does come with its own challenges. For example, one significant risk involves the use of Functional Mock-up Interface (FMI) DLLs for model sharing and co-simulation. While they facilitate interoperability and model exchange, their use bears the risk of cyberattacks. Another challenge is in the digital rights management (DRM) of corresponding models, ensuring that models cannot be reverse engineered by exploiting infinite execution or that models are shared without proper payment. These risks and challenges must be carefully managed to ensure that the benefits of model sharing are not undermined by potential vulnerabilities.
Sustaining evolution relies on technology innovation
Be it the interplay between solution accuracy and simulation speed, or the adoption of CAE by new user personas and by new industrial use-cases, the ongoing evolution of CAE will not happen by chance. We can’t rely on hardware compute roadmaps alone to sustain a continued growth in the effectiveness of CAE. Disruptive technologies are required, together with the effort and investment necessary to develop them. From algorithmic innovation and hybrid ML modelling through to generative AI automation, interoperability, and model-as-a-service, multiple opportunities exist that together will ensure CAE’s continued growth and adoption.
[1] U Rüde, K Willcox, L Curfman McInnes, H De Sterck (2018): Research and Education in Computational Science and Engineering. SIAM Review
[2] PG Martinsson and JA Tropp (2020): Randomized numerical linear algebra: Foundations and algorithms. Acta Numerica
[3] D Kochkov, JA Smith, A Alieva, and S Hoyer (2021): Machine learning–accelerated computational fluid dynamics. PNAS
[4] J Shalf (2020): The future of computing beyond Moore’s Law. Philosophical Transactions of the Royal Society A
[5] NVIDIA (2024): NVIDIA Blackwell Platform Arrives to Power a New Era of Computing
[6] T Hey, S Tansley, K Tolle, J Gray (2009): The Fourth Paradigm: Data-Intensive Scientific Discovery. Microsoft Research
[7] WIT Uy, D Hartmann, B Peherstorfer (2022): Operator inference with roll outs for learning reduced models from scarce and low-quality data
[8] B Albright (2023): Technology Outlook 2024. Digital Engineering December 2023
[9] AF Ragani, P Stein, R Keene, I Symington (2023): Unveiling the next frontier of engineering simulation. McKinsey and NAFEMS report
[10] The Economist (2022): Huge “foundation models” are turbo-charging AI progress
[11] T Abbey (2017): CAD and FEA User Interface Evolution
[12] ISO 10303-21 (2016): Industrial Automation Systems and Integration – Product Data Representation and Exchange
[13] Functional Mock-up Interface standard
[14] OMG (2024): SysML v2: The next-generation Systems Modelling Language
[15] SimScale (2023): The SimScale API
[16] Simercator – Cloud for Simulation Models
[17] Siemens (2023): Siemens and NVIDIA partner to build the Industrial Metaverse. Press Release
[18] FJ Menzl: (2021): Smart & sustainable: what it takes to create the green factory of tomorrow. Siemens Blog
[19] e.g., TurboSquid by Shutterstock
[20] e.g., 3D X exchange by Endeavor Business Media, LLC.
Disclaimer
This is a research exploration by the Simcenter Technology Innovation team. Our mission: to explore new technologies, to seek out new applications for simulation, and boldly demonstrate the art of the possible where no one has gone before. Therefore, this blog represents only potential product innovations and does not constitute a commitment for delivery. Questions? Contact us at Simcenter_ti.sisw@siemens.com.