Detection and mitigation of AI bias in industrial applications – Part 3: Mitigation strategies and examples

In parts one and two of this blog series, I explained the difference between desired and harmful biases and discussed how to detect AI bias in industrial applications. This writing focuses on mitigating the unexpected bias of AI models, a “hidden” pillar behind all other factors in trustworthiness of AI that in turn can affect manufacturing decisions. This third and final part also contains real-world industrial examples and a few recommendations.
Mitigation strategies for harmful AI bias
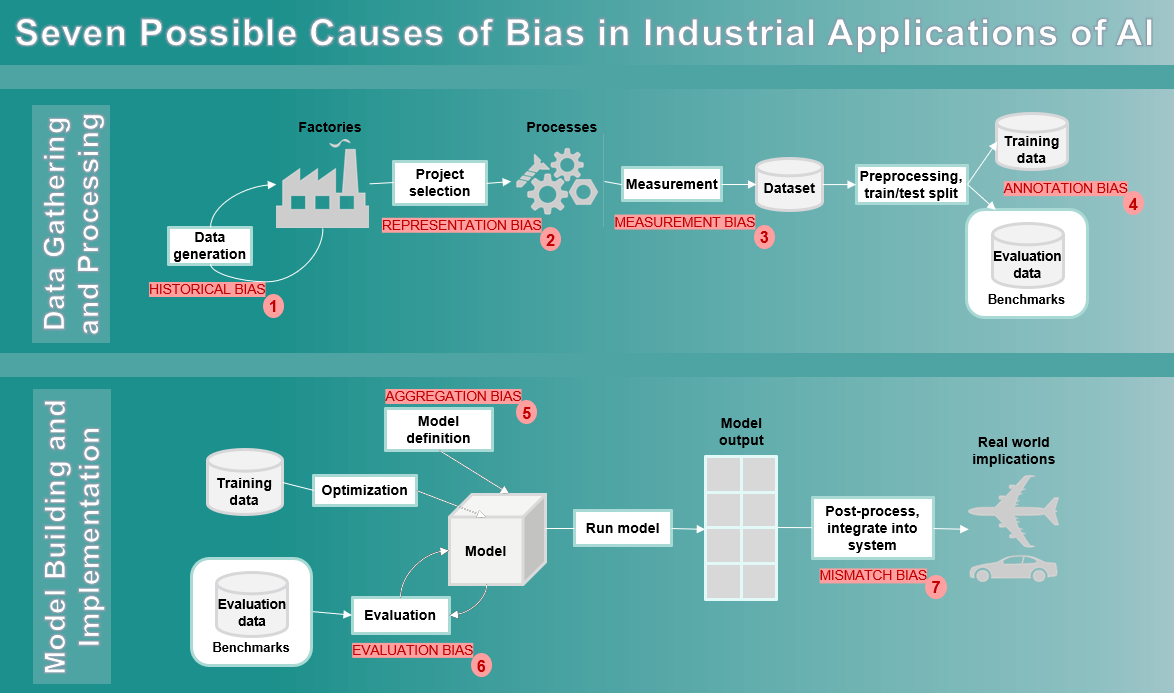
Reference [1] offers a list of tools to detect and/or mitigate bias in AI models. The top three tools that seem to be most active are: AI Fairness 360 toolkit from IBM, Fairness Indicators from Google, and Fairlearn from Microsoft. However, we should develop our own tools since mitigating industrial bias (as illustrated in the figure above) represents a unique set of challenges and opportunities not addressed by any of these toolkits. References [2] and [3] contain several algorithms that could be utilized to create such tools for industrial applications. Several other approaches are covered below:
- When evaluating the model for bias, choose the metrics of interest by involving domain specialists and affected stakeholders so that the usage and consequences of implementing the model can be fully analyzed.
- When defining the model, parametrize the various groups differently and facilitate learning by multiple simpler functions that consider group differences (i.e., capture features that may explain differences across groups of individuals, parts, products, etc.).
- Use Subject Matter Experts (SMEs) for each use-case to identify critical and redundant features. There are real examples of removing proxy dependent variables by production engineers leading to improved models. SMEs and other stakeholders can bring their varied experiences to bear on the core challenge of identifying harmful outcomes and context shifts.
- Features whose values remain constant or nearly constant should be excluded from a model. Also, use Principal Component Analysis (PCA) and Genetic Algorithms (GAs) to reduce the number of features.
- Use bias-variance trade-off analysis to understand the performance of the model relative to the training data and its parameters. Furthermore, the Random Forest algorithm can be used to output a variable importance list describing which features are relevant thus leading to model improvements.
- Use AI to monitor and explain AI/ML [4][5]. Automatically labeling hidden layers of ML with natural language descriptions of their behavior is an excellent approach for detecting bias. Similarly, model transparency can be facilitated by using systems such as the What-If Tool from Google.
- It is extremely helpful for the AI model to understand where it is being applied and the level of expertise of the person using that model in production. A generalized model can handle both “truck” definitions in USA and India (see Mismatch Bias above) if it is location aware. Furthermore, Counterfactual fairness [6] can be used to bridge the gaps between the laboratory and the post-deployment real world.
- Regarding model validation, regularization methods can be used to prevent overfitting. After implementation, models must be monitored on an ongoing basis and new models built when features and/or environments are modified or changed.
To address many of the recommendations in this section, we should define a research project to develop a “bias predictor” tool for ourselves as well as our customers that can detect harmful bias in the AI model and suggest actions to avoid its impact on business, company brand value, and fulfillment of regulatory norms.
Real-world industrial bias examples
The first example, called “Survivorship bias” [7], is a combination of Representation bias, Measurement bias, and Mismatch bias. The terminology comes from the instinct to only look at the data from “surviving machines” in the industrial context, rather than looking more broadly at the whole dataset, including those with similar characteristics that failed to perform as well. The most famous example of survivorship bias dates to World War II where data from damaged but surviving planes were initially used to determine reinforcements on the planes. But this is precisely the wrong approach because the damaged portions of returning planes showed locations where they can sustain damage and still return home; other places hit on the plane should have been considered (as they eventually were) as riskier because planes hit there presumably did not survive. For ML-related use cases, we need to perform simulation and generate synthetic data for more perilous situations that cannot be measured.
The second example comes from [8] where a forklift driver was accomplishing his assigned trips faster to gain more free time for coffee breaks. However, the AI model learned from behavioral data, and assigned more trips to that driver than to his “slower” colleagues. Here we have a combination of Historical bias, Aggregation bias, and Evaluation bias contributing to an unfair treatment of this driver.
The third example comes from our own development group. Nilesh Raghuvanshi explained: “In an electronic assembly, of the thousands of copper features on an outer board layer, a select group of features called ‘fiducials’ provide optical targets for automated assembly equipment to ensure precise alignment. The typical process is for a user to scan the features manually and identify the fiducials based on experience or tribal knowledge, which is error-prone, time-consuming, and varies per customer. We extracted data using attributes utilized by human specialists to accomplish this identification as we sought to learn this tribal knowledge using machine learning. The initial dataset showed a good correlation between the feature ‘side’ and the target. However, validation on various data slices did not produce equally good results. As we gathered more data, the correlation with ‘side’ was not valid anymore. Discussion with Subject Matter Experts revealed that the strong correlation could be specific to a certain customer but in general, the presence of fiducial should not be determined by which side of the PCB board is present. Based on this insight, we opted to eliminate this feature and mitigated the bias introduced by modeling decisions based on the initial dataset.
Another source of bias in the dataset was due to class imbalance. We worked with a dataset of around six million samples, 99.89 percent of which belonged to the normal class and just 0.11 percent of which belonged to the fiducials class resulting in a highly imbalanced dataset. This bias was found to be accurate as a typical PCB board with 8000 to 10,000 features often includes just four to five fiducials. To develop a better model, we applied approaches like random under-sampling and cost sensitive classification in order to take advantage of the ‘beneficial’ bias in AI.” This example demonstrates Representation bias, Measurement bias, and possibly Annotation and Aggregation biases.
Concluding remarks
AI continues to evolve and is already transforming industries [9], thus requiring special attention to its unique features such as bias. Bias is an inherent characteristic of AI and could be beneficial if directed properly; however, it could be a big problem if its harmful side is not detected and mitigated. The presence of harmful bias in AI models for industrial applications can contribute to undesirable outcomes and a public lack of trust. Our machine learning development processes and operations (MLOps) should provide proper training and tools to Siemens’ engineers to recognize sources of bias and implement mitigation strategies when creating and implementing these models.
Managing bias, in both harmful and beneficial aspects, is a critical but still insufficiently developed building block of trustworthiness. What is covered here is only a start for a more detailed look at this issue.
Software solutions
Siemens Digital Industries Software is driving transformation to enable a digital enterprise where engineering, manufacturing and electronics design meet tomorrow. Xcelerator, the comprehensive and integrated portfolio of software and services from Siemens Digital Industries Software, helps companies of all sizes create and leverage a comprehensive digital twin that provides organizations with new insights, opportunities and levels of automation to drive innovation.
For more information on Siemens Digital Industries Software products and services, visit siemens.com/software or follow us on LinkedIn, Twitter, Facebook and Instagram.
Siemens Digital Industries Software – Where today meets tomorrow.
References or related links
- Murat Durmus: An overview of some available Fairness Frameworks & Packages, October 2020.
- Harini Suresh and John Guttag: A Framework for Understanding Sources of Harm Throughout the Machine Learning Life Cycle, December 2021.
- Sheenal Srivastava: Eliminating AI Bias, October 2021.
- Evan Hernandez, et. al.:Natural Language Descriptions of Deep Visual Features, January 2022.
- Matthew Tierney: Researchers at U of T and LG develop ‘explainable’ artificial intelligence algorithm, March 2021
- Matt Kusner, et. al.: Counterfactual Fairness, March 2018.
- Brendan Miller: How Survivorship Bias can cause you to make mistakes, August 2020
- Rasmus Adler, et.al.: Discrimination in Industrial Setting, November 2020
- World Economic Forum: Positive AI Economic Futures, November 2021.
About the author: Mohsen Rezayat is the Chief Solutions Architect at SIEMENS Digital Industries Software (SDIS) and an Adjunct Full Professor at the University of Cincinnati. Dr. Rezayat has 37 years of industrial experience at Siemens, with over 80 technical publications and a large number of patents. His current research interests include “trusted” digital companions, impact of AI and wearable AR/VR devices on productivity, solutions for sustainable growth in developing countries, and global green engineering.


